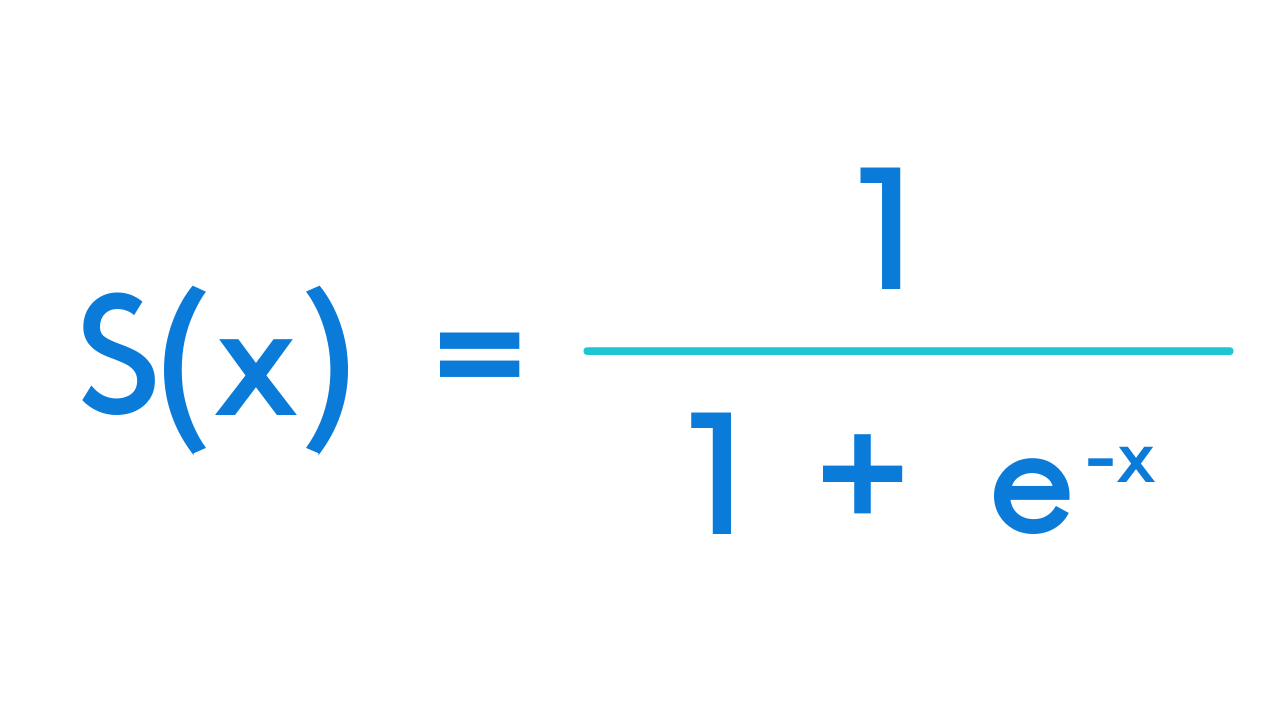Product updates, industry-leading insights, and more
How to Use Fuzzy Logic Address Matching for Improved Accuracy
by Placekey
It’s extremely common for people to make errors when inputting addresses, including formatting and misspelling mistakes. Traditional address matching is able to determine if an address is an exact match, but it does little to account for different formatting inputs and misspellings. Fuzzy logic address matching allows you to match and correct addresses that have been input incorrectly. If fuzzy matching isn’t enough, we’ll show you a great alternative in Placekey’s universal address identification system.
Rather than combing through Stackoverflow for upvoted solutions, we outline the top methods and tools for fuzzy address matching. Read on for more on the following:
What is fuzzy logic address matching?
Address matching problems fuzzy logic solves
Downsides of using fuzzy logic for address matching
Top 7 methods & tools for fuzzy address matching
First, we’ll cover what fuzzy address matching is, identify the address matching problems that fuzzy logic solves, and then dive into the best methods and tools for fuzzy address matching.
What is fuzzy logic address matching?
Fuzzy logic address matching is a system that allows you to determine address accuracy with varying degrees of certainty (rather than simply determining whether an address exactly matches or not). This can be used for address matching and address standardization, enabling addresses to be automatically corrected.
Fuzzy logic address matching uses advanced algorithms (often AI-powered) to more accurately find and distinguish between addresses. This is ideal for identifying an address, as you can still find the correct address with a slightly incorrect search input.
What is fuzzy logic?
Fuzzy logic is a form of determining degrees of value that fall between the standard “true or false” (0 or 1) distinctions present in Boolean logic. With fuzzy logic, you maintain the absolute truth values of 0 and 1, but allow for the use of any value of truth (partial truths) that falls between this. This can then be used to make determinations about the data, as well as flag certain pieces of data for correction.
Fuzzy logic can be represented using a version of a standard logistic function, refined to a value between 0 and 1.
Fuzzy address matching is a more specific version of fuzzy logic, which can be applied to all data. To help you understand the difference clearly, we distinguish the two types of data matching below:
Deterministic data matching: Identify which properties in your data you wish to compare, and look for an exact match. This system functions on a complete true or complete false system, and offers little flexibility.
Probabilistic data matching: Determine the probability of a match between records, giving you the likelihood that records completely match or not. Fuzzy matching is a form of probabilistic data matching.
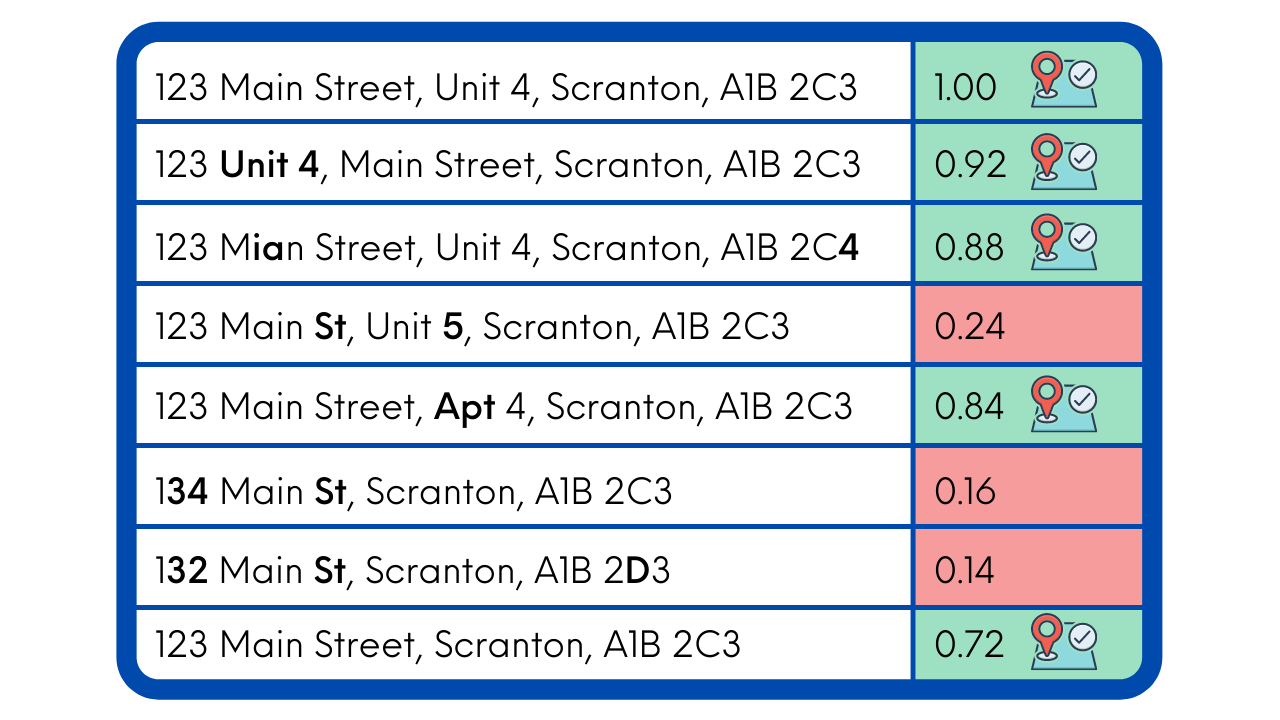
Using a fuzzy address matching algorithm, you can set a tolerance level to accept, allowing you to improve the accuracy of your results and reduce false positives. For example, you can set a threshold of 0.8, and then balance from there to ensure few false positives get through, while still returning results and allowing for misspellings, improper entry, and differing formats.
In many address matching and address standardization solutions, fuzzy logic is used to help you find the correct address when searching. This can greatly help you when you are trying to deduplicate and standardize addresses.
Address matching problems fuzzy logic solves
There are a number of issues with traditional address matching, as you need to have your data input exactly, including spelling and formatting. Fuzzy logic solves a number of problems that traditional address matching cannot:
Determine the likelihood of a full match - Rather than simply determining a full match, predict the likelihood of a full match, allowing you to make better decisions about matching data.
Address misspellings and small formatting errors - With traditional address matching, an address is either an exact match or not. With fuzzy logic, it determines the likelihood of a match, based on how many characters are different.
Difficult to deduplicate addresses - Without being able to easily pair addresses, it’s more difficult to deduplicate address data and combine your records.
Distinguishing unique address information - While you can program your exact matches to account for small differences in common formatting (i.e. street vs st, lane vs ln, avenue vs ave, etc.), this won’t account for street names and other unique address information that is not standard. Fuzzy logic allows you to set rules for address standardization, correcting address information like street names to match with better accuracy.
Impossible to identify phonetic variations - As simple address matching is looking for an exact match, they are not designed - and unable - to detect phonetic differences in addresses.
Downsides of using fuzzy logic for address matching
Fuzzy logic is typically a better method to use than traditional address matching, as it allows for more flexibility. That being said, it’s still prone to its own problems. Here are some of the main problems you’ll run into when using fuzzy logic for address matching:
Some misspellings and formatting errors will still be missed: While fuzzy logic allows you to determine the likelihood of a match, and in some cases standardize the address for you, there is still room for error. With Placekey’s alphanumeric code, you don’t have to worry about commonly misspelled street names and improperly formatted address labels (such as “St” vs “Street”).
Still challenging to deduplicate addresses: While it is simpler, there are still challenges when it comes to confirming that an address matches, and deduplicating that data. With Placekey, location, address, and POI information is embedded within the Placekey itself, making it easy to consolidate information about different Placekeys - and the physical locations attached to them.
Can’t pick up phonetic errors: Many users spell addresses based on how the street name sounds, leading to misspellings. With Placekey’s alphanumeric identification system, you never run the risk of mixing up or making errors when entering or looking up a Placekey.
Very little additional address information to verify a match: With address matching, you are comparing two records and determining the likelihood of a match. This can still lead to errors matching addresses. Placekey encodes address and location data within the Placekey, and cross references its own database of Placekey’s to deduplicate data, ensuring that you have ample data to determine if two POIs are in fact the same.
In short, while fuzzy logic solves many of the issues that direct address matching is incapable of, there are still shortcomings. Placekey’s universal identifier provides a standardized, alternative to traditional address matching, and is a simpler, more accessible, and better solution to fuzzy logic address matching.
Top 7 methods & tools for fuzzy address matching
There are a number of methods to use for fuzzy address matching. Below are the most basic and accessible methods, allowing you to start fuzzy matching immediately. Determine which methods work best for your situation, and set your thresholds accordingly.
Method 1: Using the Levenshtein Distance
Regardless of the coding environment you use to match addresses, one of the main methods for fuzzy address matching is using the Levenshtein distance. Also referred to as Edit Distance, the Levenshtein Distance is the number of transformations (deletions, insertions, or substitutions) required to transform a source string into the target one.
You can calculate the Levenshtein distance between two strings (a and b, of length |a| and |b| respectively) using the formula below:
Using this method of address matching, you can account for formatting errors and spelling mistakes that would otherwise result in a failed match. Set this up in your code, and establish a Levenshtein distance to use for matching addresses, choosing the distance you want to ensure accuracy, while still accounting for multiple mistakes.
For example, set a distance of 1 to allow for 1 character to be deleted, inserted, or substituted. Alternatively, you can expand this to 2 or 3, but this will also increase the likelihood of false positives.
Method 2: Using the Damerau-Levenshtein Distance
The Damerau-Levenshtein distance goes a step further, enabling another operation for data matching: transposition of two adjacent characters. This allows for even more flexibility in data matching, as it can help account for input errors. It can be used to assess a relation between two records more accurately.
You can calculate the Damerau-Levenshtein distance between two strings (a and b), we use the function below, where the resulting value is a distance between an i-symbol prefix of string a and a j-symbol prefix of b.
For example, when someone types “BANR”, it needs to be corrected to “BARN”. To correct this using the Levenshtein distance, you would have a distance of 2 (replacing N with R and R with N). To correct this using the Damerau-Levenshtein distance, you would have a distance of 1 (swapping the R and N); while the result is the same, you can determine a match with greater likelihood.
While this method predicts a match with greater accuracy, it is more prone to errors, as it will correct false positives. If you’ve ever used text correction, you are familiar with how these systems work in action, correcting words based on the word you are most likely trying to type. While more often than not, this works to your advantage, the odd time, it makes a mistake, and autocorrects when it shouldn’t.
Method 3: Clean your data thoroughly before processing
As you can imagine, the more distance you allow for using the Levenshtein or Damerau-Levenshtein distances, the greater room for error there is. To reduce errors that result in false positives and improve your ability to accurately match addresses, you will need to clean your data before processing.
To do this, you are only cleaning your address data in a way that allows for easier and more accurate matching. Cleaning involves standardizing the formatting of specific address components. For example, all synonyms for Avenue (Av, Ave, etc) to one version, Avenue. Another good use case of this is Apartment, Apt, #, Unit, and other formats commonly used to indicate an apartment unit.
This way, you can refine your levenshtein distance when automating your search, ensuring more accuracy in your results. Having already cleaned your data and accounted for synonyms and case sensitivity, you will lower your rate of errors. You can then refine your distance, and produce more accurate matches.
Method 4: Parse data prior to processing for greater accuracy
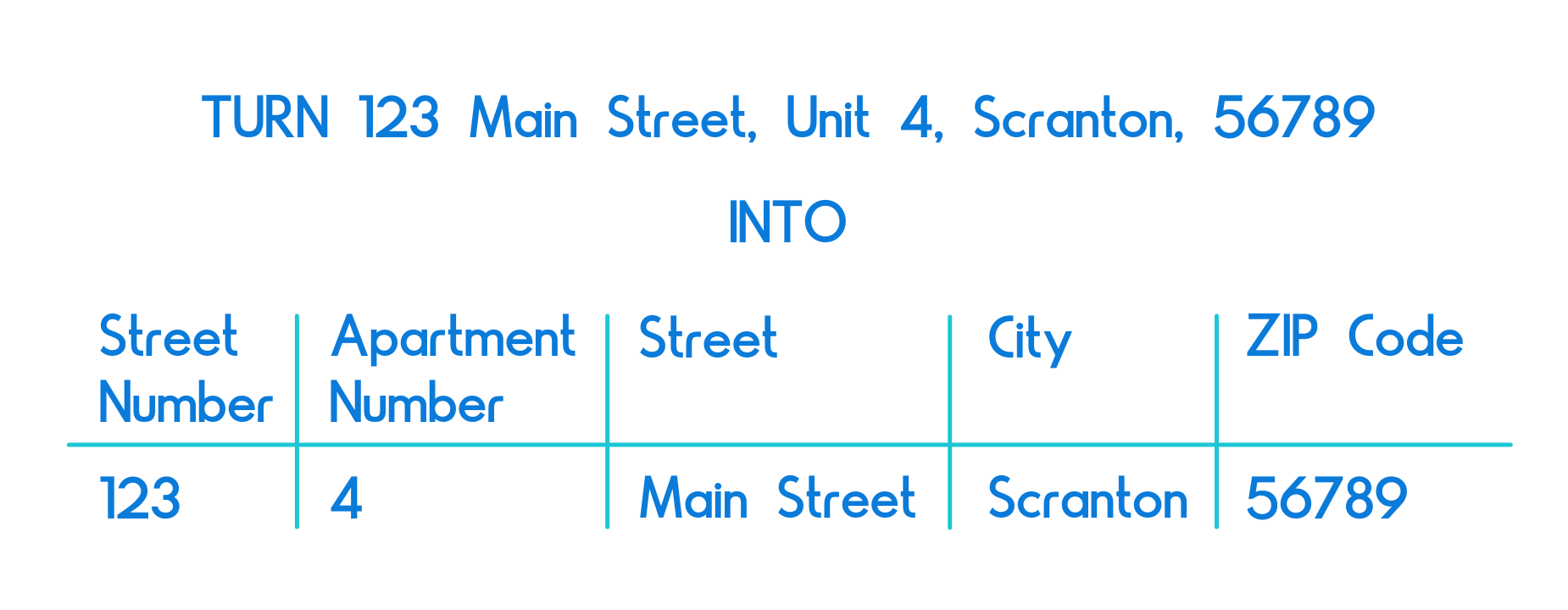
Even if you’ve used a combination of the first 3 methods, you may still find you are having a problem matching data easily. It’s suggested that you parse your data before processing it. In the case of addresses, this would mean splitting out the number, street name, city, postal code. With each piece of information separate, you can then accurately match each separate piece.
With your data segmented in this way, you can set up conditional formatting that will make it easy to quickly compare addresses for matches. Set up restrictions so you only compare addresses within the same city or state, reducing processing time. It also makes using the Levenshtein and Damerau-Levenshtein distances easier, as you can compare each element in this way, rather than the entire address.
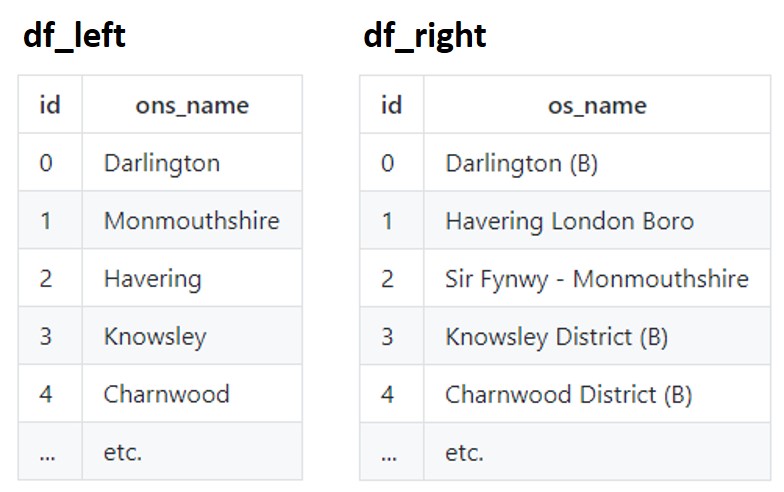
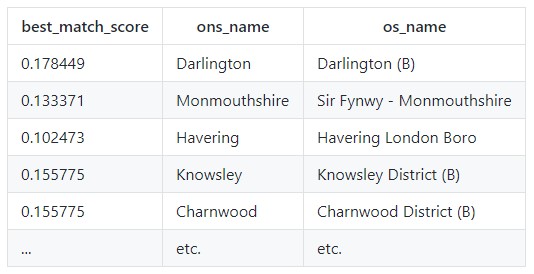
Fuzzymatcher is a Python package that enables the user to fuzzy match two pandas dataframes based on one (or more) common fields. It utilizes sqlite3’s Full Text Search to find matches, and then uses probabilistic record linkage to provide a score for these matches. It outputs a list of matches, along with their quality score. You can then use this information to determine the likelihood of a true match.
With fuzzymatcher, you can pair two address tables and find their match score rating.
You can even set up a threshold so that addresses can be automatically identified as either true or false. A threshold of 0.8 or higher is recommended, to account for false positives.
The Python Record Linkage Toolkit is designed to link records, allowing for deduplication and data management. It leverages Python’s pandas, which is a flexible data analysis and manipulation library built for Python to identify matched addresses based on parameters. The solution will output a match score, after measuring the similarity between strings.
Install the library using pip, and then set up an explicit index column to read in the data:
Next, you need to define linkage rules that will be applied, to take advantage of Record Linkage Toolkit’s more complex configurations. Start by creating an indexer object:
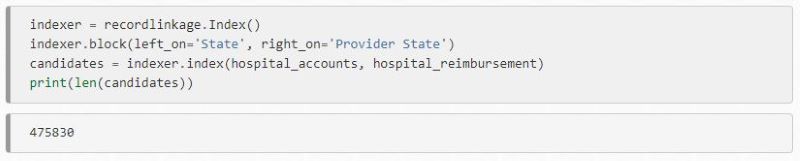
You can use a full indexer to evaluate all potential matches. The only downside is that this can result in many paired records, some of which are incorrect. It will also likely mean too much unrelated information is captured. Before running a comparison, you can see how many comparisons will be ran by doing the following:
As you can see, you can specify your comparison based on a number of factors. You can use this to customize it to the task you are trying to perform, as well as refine your search for addresses in a number of generic ways. Set up thresholds yourself to define what results are returned.
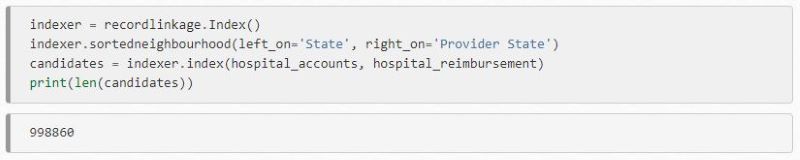
You can also refine your comparisons using blockers, ensuring that for a match to occur, certain criteria has to match. For example, if you are trying to deduplicate addresses, you want to restrict your comparisons to addresses within the same region, such as a city or state.
This refines your comparison to the relevant data sets, only comparing addresses within the defined area (city, state, country, etc.). With less data to process, you can match addresses faster, as this will actually run much faster, without comparing irrelevant data sets.
Since this will use a rigid true or false condition, we need to employ another blocker to allow for matching addresses with improper spelling. A SortedNeighborhood algorithm will allow for misspellings, such as “Tenessee” vs “Tennessee”.
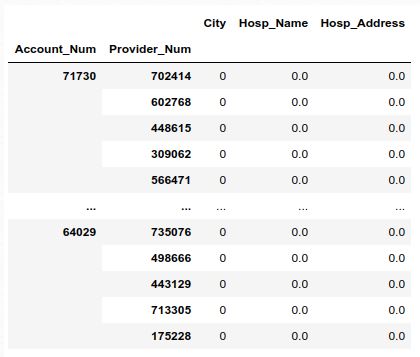
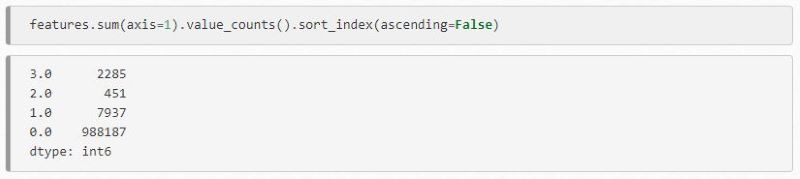
Once you’ve applied these blockers, you will end up with a features DataFrame displaying all of the comparisons you set up. Columns match with the comparisons you defined before running it. In the results table, a 1 notes a full match, and a 0 notes a full negative.
With this information, we can then determine how many matches we have, and to some degree, the quality of those matches (via how many matches there are).
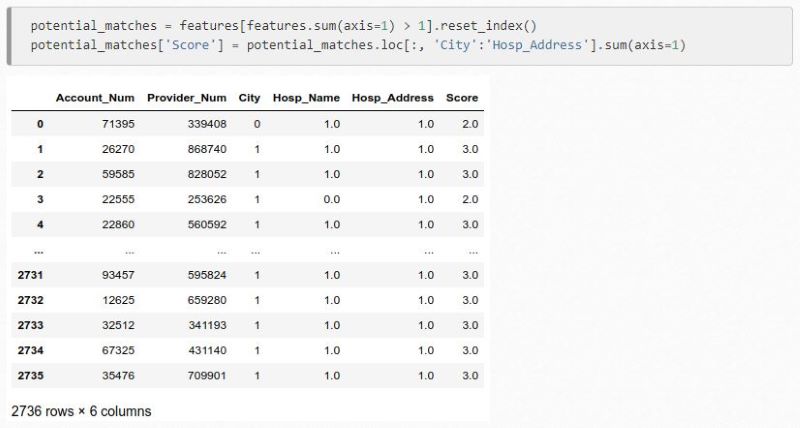
With this information, we now know how many matches exist within the rows, as well as how many rows have no matches. Going on the example above, the rows with multiple matches are most likely to be accurate. You can compare these data sets and add quality scores to determine how likely of a match they are:
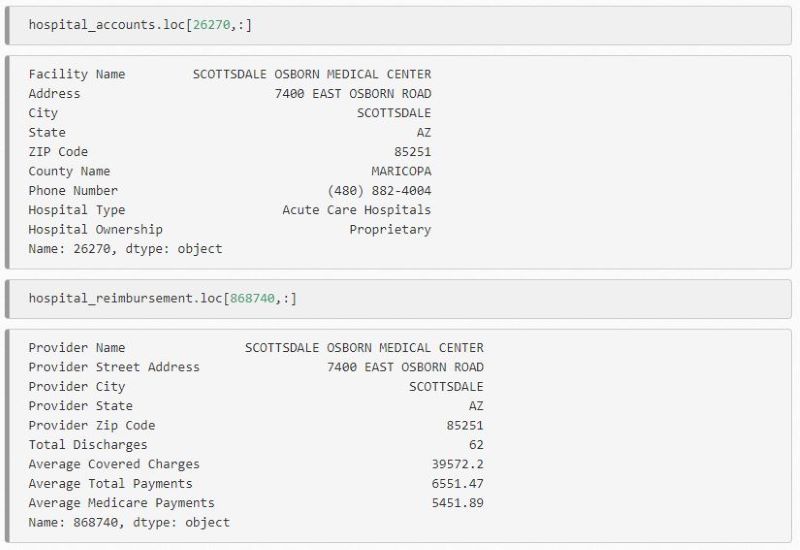
You can then use this to identify what data matches, and find identical address matches. Once you think you have a match, pull up their individual records and identify if they are a match or not:
The Levenshtein and Damerau-Levenshtein distances struggle to match address information that is out of order. While addresses generally have standardized formatting that many people follow, they can be input in different orders. For example, an address can be entered as follows:
123 Main Street, Unit 4
123 Unit 4, Main Street
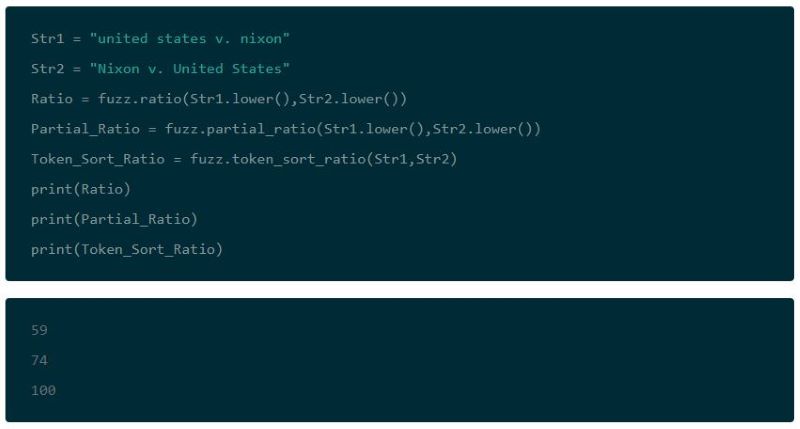
In the case above, the Levenshtein difference would not match these two addresses, unless the threshold was set very high (which would result in far too many false positives for this to be effective). FuzzyWuzzy solves this by tokenizing strings and preprocessing them by removing punctuation and converting them to lowercase.
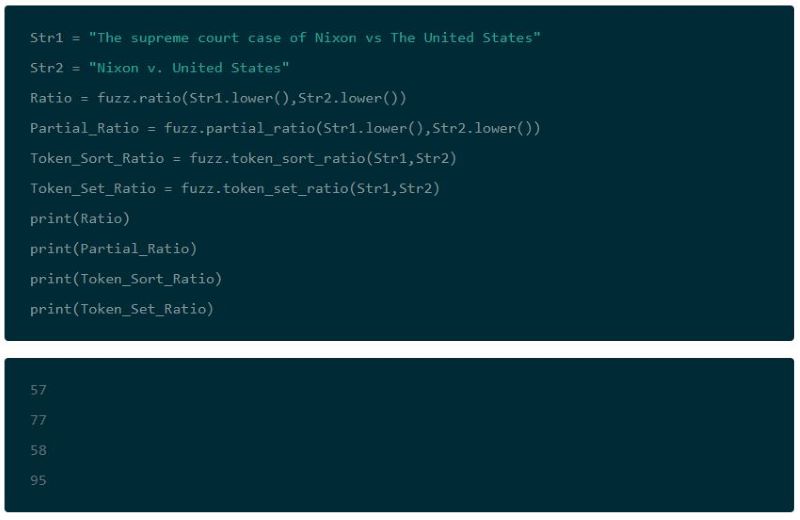
This allows you to match addresses that have been input using a different order:
This also lets you match entirely different input formats. If a user were to input a sentence with address information, you could still potentially pair address data.
These strategies greatly improve your ability to accurately match addresses, and can enable better deduplication and standardization, so you can identify addresses with more clarity and specificity.
Now that you know what fuzzy logic is, you can use it with address matching, helping you be more flexible in your address matching, ultimately improving accuracy. Use the methods above, and see more tips for using python or SQL specifically. Leverage the Levenshtein and Damerau-Levenshtein distances, testing different thresholds for determining a match.
Over time, this will improve address matching accuracy and allow you to automate more of this process. Alternatively, you can see how Placekey works and learn why it’s a better method than address matching, offering a universal identifier for addresses.
Placekey
Placekey is the universal standard identifier for a physical place. Learn more about us at Placekey.io.
Get ready to unlock new insights on physical places