Product updates, industry-leading insights, and more
The Address Matching Challenge – Solved!
by Placekey
It’s been said that 90% of the world’s data has been produced in the last 2 years. But what’s less known is that 90% of that data is unstructured and 95% of businesses cite the need to manage unstructured data as a problem for their business.
One of the biggest unstructured data points is an address.
Which makes address matching, the process of joining records from multiple datasets to identify matches, a downstream challenge.
Address matching is a crucial step in geocoding and the goal is to match a desired address in a dataset (example: homes hit by a natural disaster) with one in another dataset (example: insurance company’s policy holders) so that the matched addresses can be placed on a map. Despite the fact that we are awash with location data, most addresses are still stored as text versus a geographical coordinate. Take any database that has the potential to be mapped and chances are each record will be stored as an address versus an X,Y coordinate.
What should be so simple is anything but. Data is often messy and address matching suffers the consequences. Take two addresses which clearly refer to the same location, but they won’t match due to typos, misspellings, abbreviations, hyphens, different zip codes and all the different ways in which addresses can be interpreted.
In this article, we’ll dive into the following:
The traditional approaches to address matching
The pros and cons of each approach
A solution that solves the tough problem of address matching
Traditional Address Matching Approaches
Address Matching Approach #1: Fuzzy Matching
Fuzzy matching, also known as probabilistic data matching, uses algorithms to account for all the possible variations for why addresses won’t match. These variations could include missing data from user input, spelling errors, punctuation differences, abbreviations, acronyms, name variations, etc. By building a buffer or threshold into the algorithm, fuzzy matching identifies the probability that two records are a match based on predetermined parameters. Using fuzzy matching, one could assume all state abbreviations for Pennsylvania begin with the letter P or all zip codes for a town are the same. This greatly simplifies the matching process.
PROS:
Easiest address matching method
Availability of multiple software programs to perform fuzzy matching
CONS:
Time consuming on false positives: two records could show a 60% probability as a match when the human eye can easily detect there is no match. These false positives are typically flagged however they will need manual human intervention to review each false positive which can be time consuming depending on the size of the databases.
Matches are missed all together: If the parameters for address matching are too low, there’s a chance that matched addresses never get flagged which can create business risk depending on the address matching use case.
Address Matching Approach #2: Complex query
With a complex query, a programmer writes a very detailed script in excel or SQL that accounts for all the idiosyncrasies between two addresses with the goal of returning a match. Complex queries give the user fine grained control over how they want to link two address fields by manually addressing all the possible outcomes or other unique possibilities in addresses.
PROS
Control: Because the queries are manually written, users have complete control over the process and can account for issues as they come up and adjust the query. For example, a complex query could take into consideration all the zip codes for a city beginning with “920” and drop the last 2 digits or utilize a look up table for state abbreviation possibilities or state misspellings.
CONS:
Very specialized and requires a programmer who understands scripting language
More recently, address matching has been helped along by advances in machine learning. Machine-learning models find patterns in massive datasets, learn from those patterns and then become more accurate over time without the need for further programming. For example, ML could learn the multiple ways in Los Angeles is misspelled (Los Angelenos, LA, L.A., LosAngeles), know to look for that and then correctly identify these misspellings. Computer algorithms would treat the misspellings as equal.
PROS
The process is completely automated and is highly accurate in catching the mistakes and linkages.
The computer can handle a huge amount of data and processing without user interaction and train itself as it works.
CONS
Machine learning is only as good as the data that is fed to the algorithm and when something goes wrong, it can really get out of control fast. If there is not enough data to train the model, it could start missing patterns and create false positives.
Machine learning is highly specialized and also requires someone with deep knowledge to set up and run the model.
Address Matching Approach #4: Spatial Joins
With a spatial join, instead of matching on text based fields and unique identifiers in a dataset, data is joined from two geographic tables (often referred to as a layer) using common spatial objects, usually a point. It takes a geocoded result and compares it against another geocoded result. If those points appear within the set buffer (e.g. 10 meters) they would be considered equal.
PROS
Spatial joins are software supported (GIS software), easy to perform and can be very accurate.
CONS
The process is slow and can take hours, if not days and requires expensive software
Accuracy diminishes in urban areas or dense environments (apartment buildings, offices) and users can end up having geocodes on top of each other.
It’s clear that traditional address matching approaches are not without their pros and cons, and that most approaches are still incomplete. What’s missing in all of this is a STANDARD.
A New Standard for Address Matching: Placekey
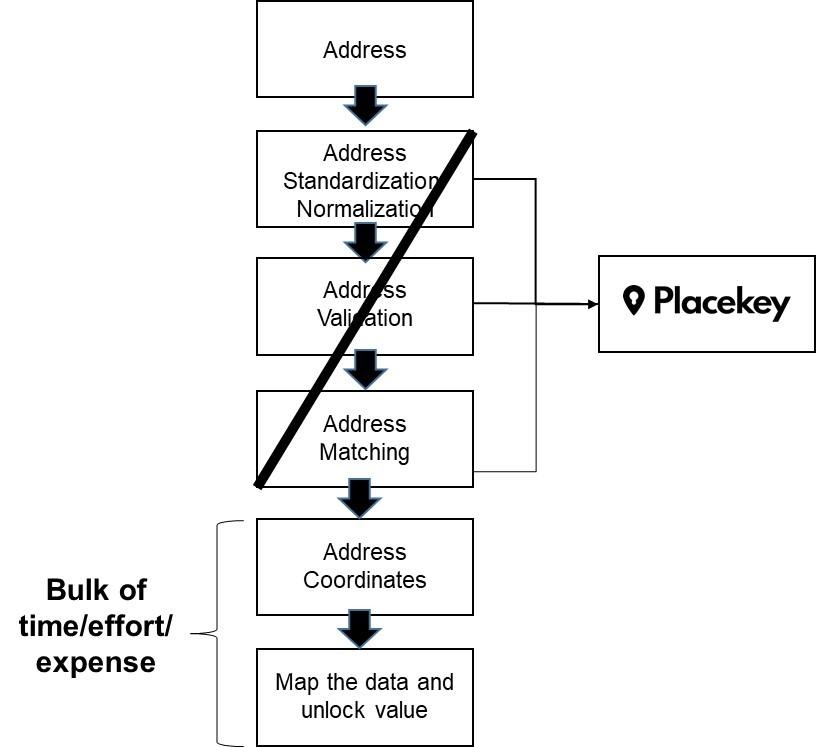
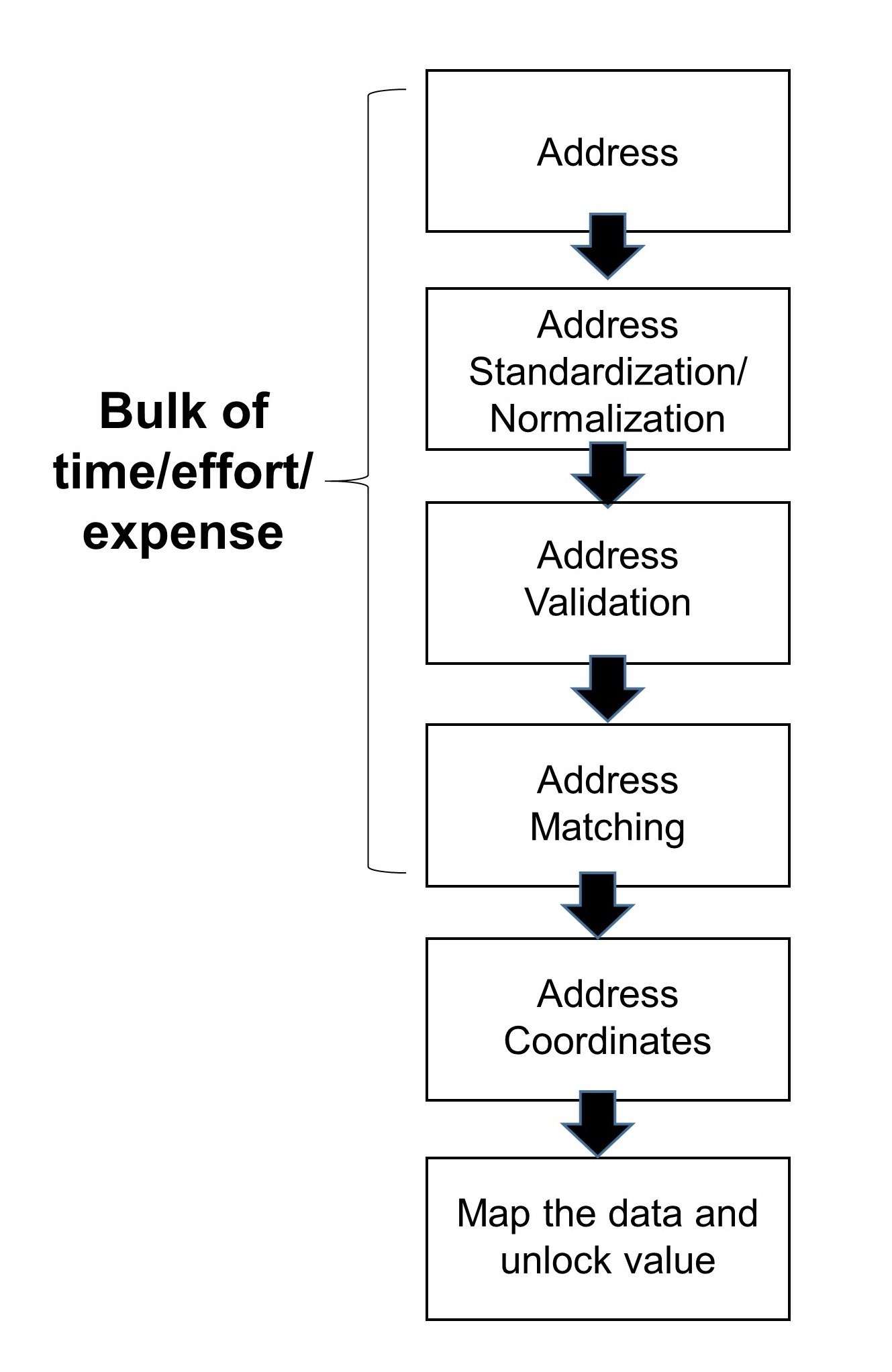
As the previous examples have demonstrated, address matching can be an arduous, expensive and time-consuming problem. Not only that, address matching is but one of multiple steps in a workflow. Before addresses can be matched, they need to be validated. And before addresses can be validated, they need to be standardized/normalized. It’s not uncommon for data science teams to spend the bulk of the time/effort on the part of the workflow that returns matched addresses. But the real value of address matching comes from the insights and experiments that can be run when matched addresses are mapped.
Placekey flips the paradigm so the bulk of the effort happens on the back-end, not the front end. By flipping the paradigm, data science teams can spend more time on the robust analysis and insights to unlock the value of geospatial data.
ADDRESS MATCHING BEFORE PLACEKEY
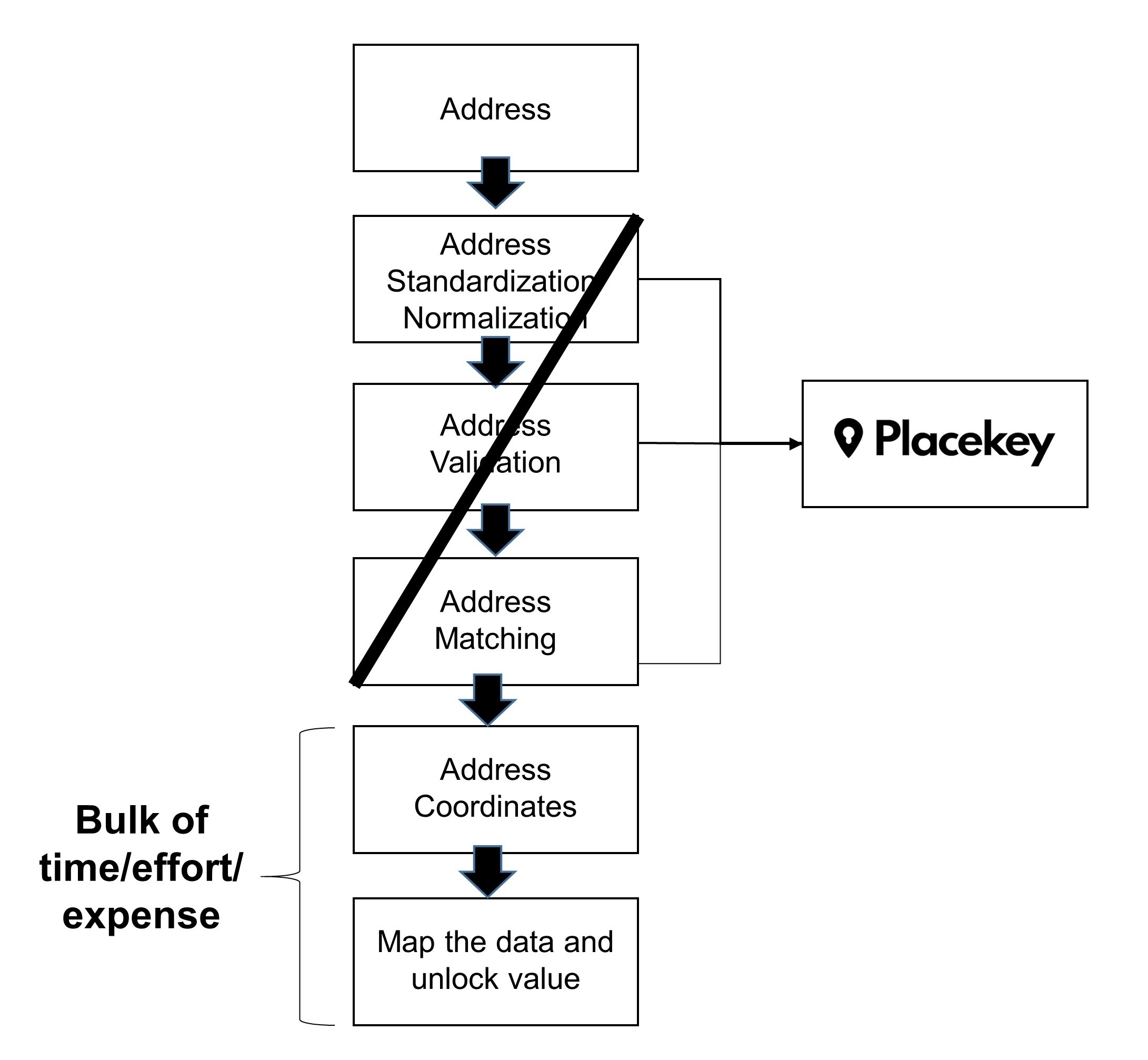
ADDRESS MATCHING AFTER PLACEKEY
How Placekey Works for Address Matching
With Placekey, address matching is no longer necessary – at least not in the traditional way. Instead, during the address standardization/normalization stage of the workflow, each address in each of the databases is assigned a Placekey.
Instead of 3 steps in the workflow: Address Standardization/Normalization, Address Validation, and then Address Matching, all these steps are collapsed into one step: assign a Placekey.
Instead of matching on the address, users can match on a Placekey.
And as an added bonus, anyone that knows how to manage a spreadsheet can streamline their workflow and start using Placekey right away with Placekey’s no code integration - no coding or technical prowess required.
Problem solved!
Now data science teams can easily combine different datasets and spend their effort wrangling experiments, unlocking geospatial insights and intelligence, and continuing to provide value to their business or institution.
For example:
A commercial real estate developer can have more time to discover the best locations that will address the most profitable customers
An insurance company can find all homeowners in a region impacted by a chemical spill.
A retailer can link up multiple customer databases to create a complete database of customer locations.
And for data providers, Placekey ensures that users can get maximum value out of the data by making it much easier for users to combine internal or external datasets
To see all of Placekey’s pre-built integrations that will speed up your workflow, visit our integrations page.
For a complete step-by-step overview on joining addresses with a Placekey, visit our tutorial.
Placekey
Placekey is the universal standard identifier for a physical place. Learn more about us at Placekey.io.
Get ready to unlock new insights on physical places