Product updates, industry-leading insights, and more
The Most Common Address Standardization Problems — and What You Can Do
by Placekey
Say “address standardization” to a data scientist and, chances are, you’ll see a flat expression or eyes glazing over.
What you won’t get is a burst of enthusiasm.
You see, because like the TSA lines and the long airplane ride that gets you to where you really want – your vacation destination, address standardization is the dread inducing but necessary step that gets you to where you really want – insights and analysis from merged data sets.
Conventional wisdom dictates the following:
Before experiments can be run, addresses need to be matched. And before addresses can be matched, they need to be standardized. So address standardization is one of several steps in a workflow for address cleansing. How “clean” data is has long been hailed as one of the greatest contributing factors to the success or failure of a geospatial project. Address data gets “dirty” from data entry mistakes, non-standard abbreviations, missing fields and attribute orderings.
And the standard for what makes an address clean versus dirty is the USPS database.
Address Standardization: The process of converting addresses to conform to USPS conventions by changing “Avenue” to “Ave”, replacing “#” with “STE” and other uniformity standards. The data first needs to be matched against the USPS database for it to be considered standardized.
Address Normalization: If a match for an address can’t be found in the USPS, then it can be normalized and formatted to conform to USPS conventions but not matched against the USPS.
Let’s just go ahead and call out what we instinctively know but may have not been able to express: address standardization has a strange alliance with the USPS and it’s creating a lot of problems for geospatial data scientists.
The Problems with Address Standardization
Challenge #1: The USPS doesn’t really care about address standardization
We as geospatial data scientists care greatly about address standardization because we assume that if the address is standardized, it will be the same across multiple data sets, and then it can be matched.
But here’s the thing: the USPS doesn’t really care about address standardization. What they care about is mail deliverability. That is their primary use case. Our postal workers work through rain, snow, sleet and the occasional aggressive canine to complete their appointed rounds for mail delivery. In fact, CASS (Coding Accuracy Support System) certification is the software used by many address standardization vendors under the presumption that when run through this software, an address is standardized and will be the same in every instance. But in reality, what CASS certification validates is whether or not the address is deliverable. And even if CASS certification says an address is standardized, that address won’t be consistent and uniform every time.
Challenge #2: It’s time consuming for a lot of minutiae
Standardizing just one address to conform to the USPS standards can be time consuming and full of minutiae. Now multiply that by tens of thousands of records and then multiply that by multiple data sets and multiple sources with user inputted data.
Yes, address standardization software automates a significant part of the process, but it still relies on human intervention to address the complexity of addresses, ensure consistency and review outcomes. And that takes time.
Challenge #3: Address standardization software helps – but only to a point
There’s no question that address standardization software helps to conform addresses to the USPS standard so that “avenue” is spelled “AVE”. But here’s what also happens: an address can get a complete override so that it is recognized by the USPS, essentially changing a result in a database. But what if you’re not sure whether that address should be changed? For example, anytime a user enters address data into a database, there is some intent behind the why of how they enter that address. Many times, especially in rural areas, the user knows more about that address location than any 3rd party software because they are boots on the ground. Remember, address standardization cares about mail deliverability. What happens when the mailbox is at the end of the highway but the physical location is at a different address? The user knows that and may in fact enter in a different address (the real physical address) versus the one that the USPS knows. Address standardization essentially overrides this human intent.
Challenge #4: Zip+ 4 codes often change
It is often assumed that utilization of the USPS ZIP+4 database will help to uniquely identify an address. But ZIP+4 codes are based on delivery routes. The additional four digits helps hone in on a more specific geographic segment within the 5 digit zip code delivery area. This can be a city block, a cluster of apartments or anything else that will help the mail carrier - in other words, the actual physical path the post office truck will take. And because of that, the + 4 on a zip code can change as much as once a month based on how many postal employees are working and who is working what route.
Challenge #5: Just because an address is deliverable doesn’t mean it can be geocoded
Let’s start at the basics of why we standardize addresses in the first place as geospatial data scientists. It’s for the geocoding! But because the primary use case for address standardization from the USPS is for deliverability, this means that a single address can have multiple delivery points. Think of individual suites in a very tall skyscraper, a P.O. Box, a mailbox at the end of a driveway, a government agency or a college campus. Same address with multiple delivery points. Yes, deliverable but no, can’t be geocoded.
Challenge 6: Even if addresses are standardized – they still might not match
Getting a 100% match on addresses would be a pipe dream. Even 80 % would be considered successful. But in most cases, it’s typically 70%. And the reason is that address standardization tools cannot validate every address. So even if you’ve changed “ave” to “AVE” and “Suite 200” to “STE 200”, that perfectly standardized address may not even appear in the USPS database. And if the address isn’t in the USPS database, it can’t be validated, and then it can’t be matched. Why does this happen? Many times, an address is not registered in the USPS database because it does not belong to a customer, is marked “vacant”, is a new address or is an unregistered address. Or it could be an address that is located in an area where there’s a lot of P.O. Boxes.
With all these challenges, you may be left wondering who invented the current paradigm of address standardization?
Address Standardization has been a force of habit. And habits are hard to change.
For too long, the current address standardization process has become a force of habit. It goes something like this:
To truly match and unify data, the data must be run through address verification software to correct errors and standardize address values
There needs to be consistency and uniformity in every data field
If there’s consistency and uniformity in every data field, the addresses will match
This force of habit has been perpetuated in schools and businesses and for anyone that works with customer data.
And it’s represented in the workflow below:
For too long, USPS conventions have been considered the “gold standard” for address standardization.
“A standardized address is one that includes all required address elements and that uses the Postal Service standard abbreviations (as shown in this publication or in the current Postal Service ZIP+4 file).”
These required address elements include a street name, number and type, prefix and suffix directional, unit type and number, USPS Zip code and state.
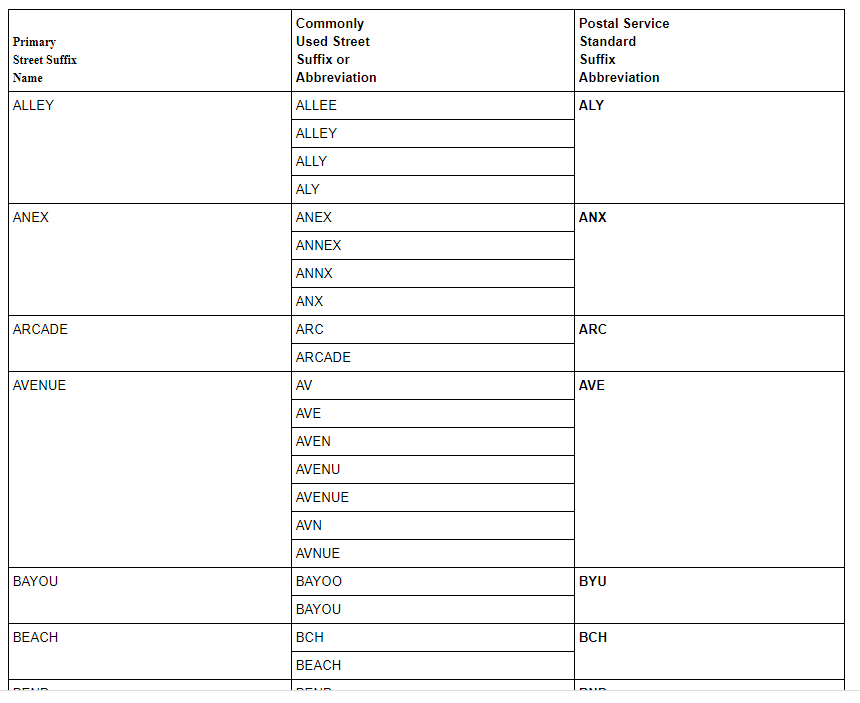
And the Postal Service standard abbreviations are plentiful. In fact there’s an entire publication devoted to just this topic. Here’s an example of how a primary street suffix should be abbreviated so it can be standardized.
And here’s some more approved abbreviations:
So, an address which contains all the necessary elements of an address as well as the correct abbreviations would be considered a “gold standard”. Here’s what this looks like according to the USPS.
What if the USPS Gold Standard is dated and stuck in a time warp?
Let’s say you have two datasets and what’s clearly the same address shows up as follows:
Database 1:
Target2
626 E Stone Drste 90
Kingsport, TN
37660
Database 2:
Target
2626 Stone Drive East
Kingsport, Tenn
37660
If we could wave a wand and say “match”, that would be great. But multiply this problem by thousands or tens of thousands of records and you quickly see how unfeasible this is.
The only way these addresses would match would be if they were both standardized to the USPS gold standard:
TARGET
2626 E. STONE DR
KINGSPORT, TN 37660-5883
In other words, the only standard for understanding an address is the USPS database. But as we’ve previously pointed out, standardized addresses were originally created for mail deliverability – not address matching. The USPS really doesn’t care about your cool new geospatial project.
Address Standardization needs a new Gold Standard. That standard is Placekey
Now are you ready for something mind-bending? Let’s take the previous example of the Target address.
PLACEKEY UNDERSTANDS THE ADDRESS SO YOU CAN MATCH DATA WITHOUT HAVING TO STANDARDIZE AND NORMALIZE!
Placekey collapses the multiple steps of address standardization/normalization, validation, and matching into one simple step: producing a simple identifier that uniquely identifies a place.
That simple identifier is called a Placekey.
Once each of the datasets resolve to the same Placekey, the data can be matched and merged…and then the real fun begins, like what happens when you merge purchase intelligence data and places data. Read more here.
Here’s what that means:
All these address standardization challenges that you’ve been struggling with – disappear.
When it comes to these time consuming problems, the only thing you need to do is, ignore them, set them aside, and banish them forever.
You can now unlearn the habit that says the only way to match addresses is to standardize them according to USPS conventions.
It’s time to challenge the notion that the only way to truly understand an address is if “street” is spelled “ST”, if “suite” is spelled “STE” or if a zip code is not a zip code unless it has a + 4.
Because now, nobody understands an address or location quite like Placekey.
It’s like getting to your vacation destination at warp speed. Spend more time generating business intelligence to drive site selection, geo-marketing, fraud detection and any other geospatial data ambition!
And for data providers, Placekey ensures that users can get maximum value out of the data by making it much easier for users to combine internal or external datasets
To see all of Placekey’s pre-built integrations that will speed up your workflow, visit our integrations page.
Placekey
Placekey is the universal standard identifier for a physical place. Learn more about us at Placekey.io.
Get ready to unlock new insights on physical places