Placekey is a useful tool for address validation. When using Placekey for address validation, we assume the following:
A location that is given a Placekey is a valid address.
A location that is not given a Placekey is not a valid address.
In reality, there are some important considerations.
An address that is not given a Placekey is not necessarily invalid...it's only probably invalid.
(?) Fuzzy match on addresses may result in addresses with errors coming back as valid.
There's no functionality to standardize addresses.
Imports and Installations
In the first code block, we install the Python Placekey package in our Google Colab environment and import the necessary packages.
!pip install placekey
from placekey.api import PlacekeyAPI
import placekey as pk
import pandas as pd
from ast import literal_eval
import json
from google.colab import drive as mountGoogleDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
Authentication
Run this code block to authenticate yourself with Google, giving you access to the datasets.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
print("You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!")
You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!
Set API key
Replace the asterisks below with your Placekey API key. If you don’t have one yet, it’s completely free.
placekey_api_key = "H3qh2FFXfCggNy8abLGvzOZfRaKpJkWZ" # fill this in with your personal API key (do not share publicly)
pk_api = PlacekeyAPI(placekey_api_key)
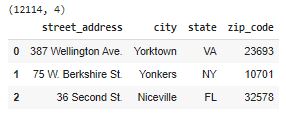
We filter to 10,000 random addresses from our dataset.
real_addresses = real_addresses.sample(10000)
We standardize the columns to (a) conform to the Placekey API and (b) allow for concatenation with the fake addresses so that we can send all API requests together.
We combine the datasets into one so that we can send all Placekey API requests together. We also shuffle the order so that the valid and invalid addresses are not all grouped together. The valid column indicates whether or not the address is valid.
There are several ways to add Placekeys to a dataset (including some no-code integrations!), which you can find on the Placekey website. In this example, we will use Python’s Placekey package.
Map columns to appropriate fields
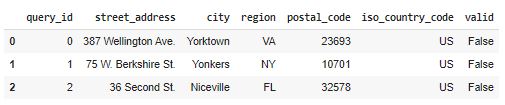
In this step, the columns are renamed to conform to the Placekey API. Since we already renamed the columns of our dataframes when we concatenated the real and fake addresses into one dataframe, all we have to do is drop valid.
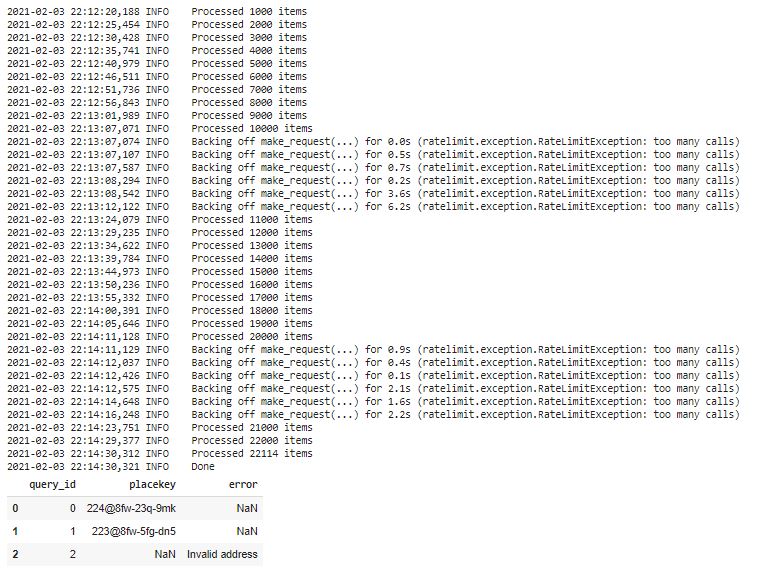
We are ready to assess the accuracy of our Placekey address validation. Remember - our assumption is that an address is valid if and only if it is given a Placekey. The following codeblock computes basic measures of accuracy for our real and fake addresses.
This tutorial was an introduction to address validation with Placekey. With our samples of real and fake addresses, we had an accuracy of over 98% in using Placekey to determine address validity. This includes a sensitivity of about 96.8%, meaning that 96.8% of valid addresses were correctly identified as valid. Additionally, our specificity was about 99.3%, meaning that 99.3% of invalid addresses were correctly identified as invalid.