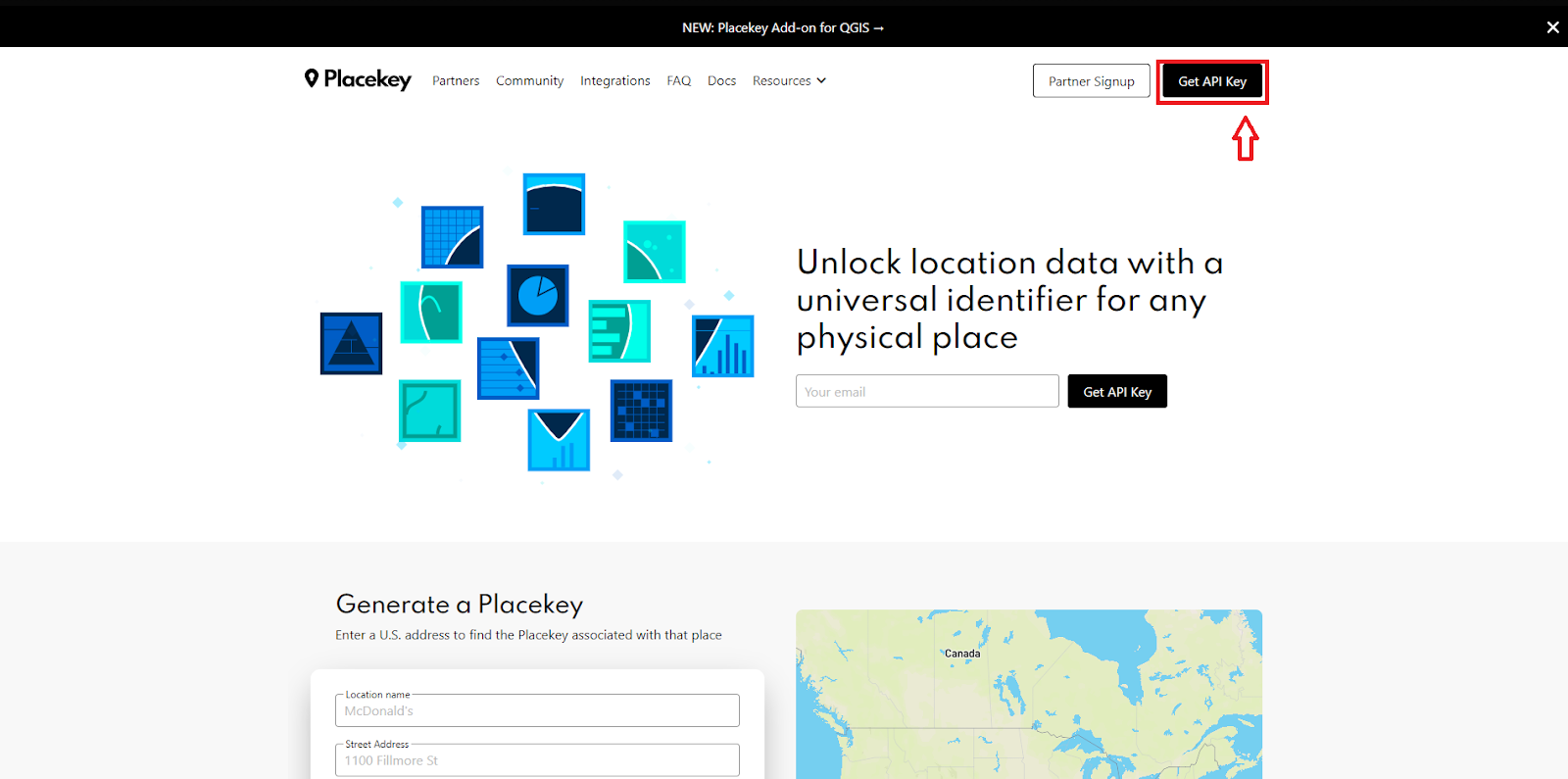
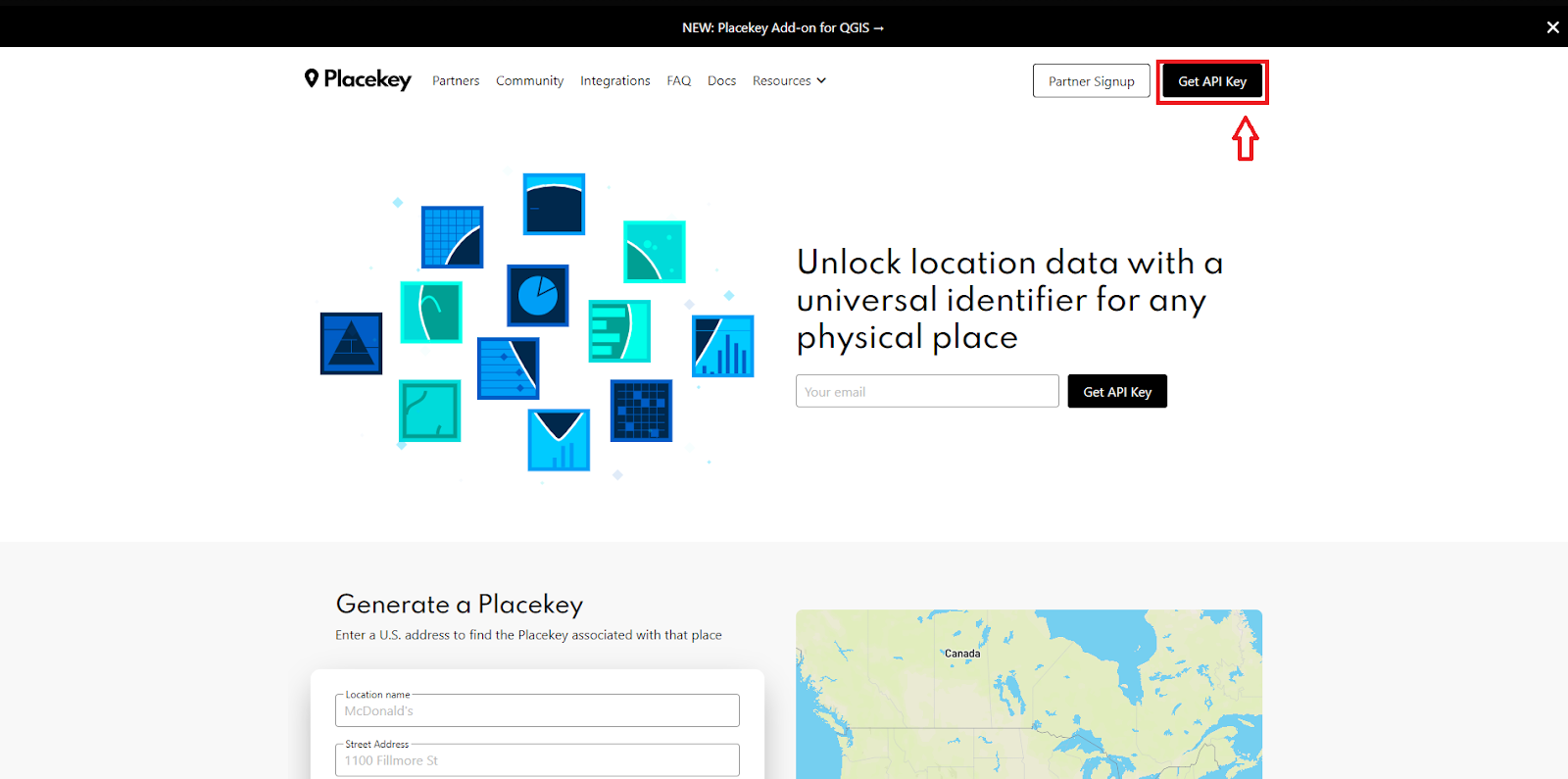
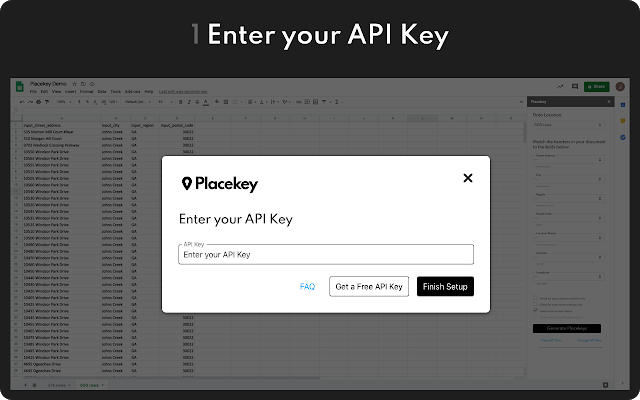
1. First off, you need to get a Placekey API key from Placekey’s website.
2. For this tutorial, we will be using Fast Food Restaurant locations around the U.S. - you can find the data HERE.
Code vs Non-Code
Placekey is constantly expanding the non-coding options available to users making it easier and easier to add Placekeys. We will discuss one option for No-Code and one option for Coding in this tutorial:
Option 1 (No-Code): Google Sheets Placekey Add-on
Option 2 (Coding): Python
Note: Both the Code and Non-code options are valuable in their respective ways. I typically use the Non-Code options for files with less than 10,000 rows and the Code option for the 10k+ rows (batch processing) - This does not mean the Non-Code methods cannot handle larger files, 10k is just my personal cutoff point.
1. Start a new spreadsheet by clicking on tile labeled ‘blank’
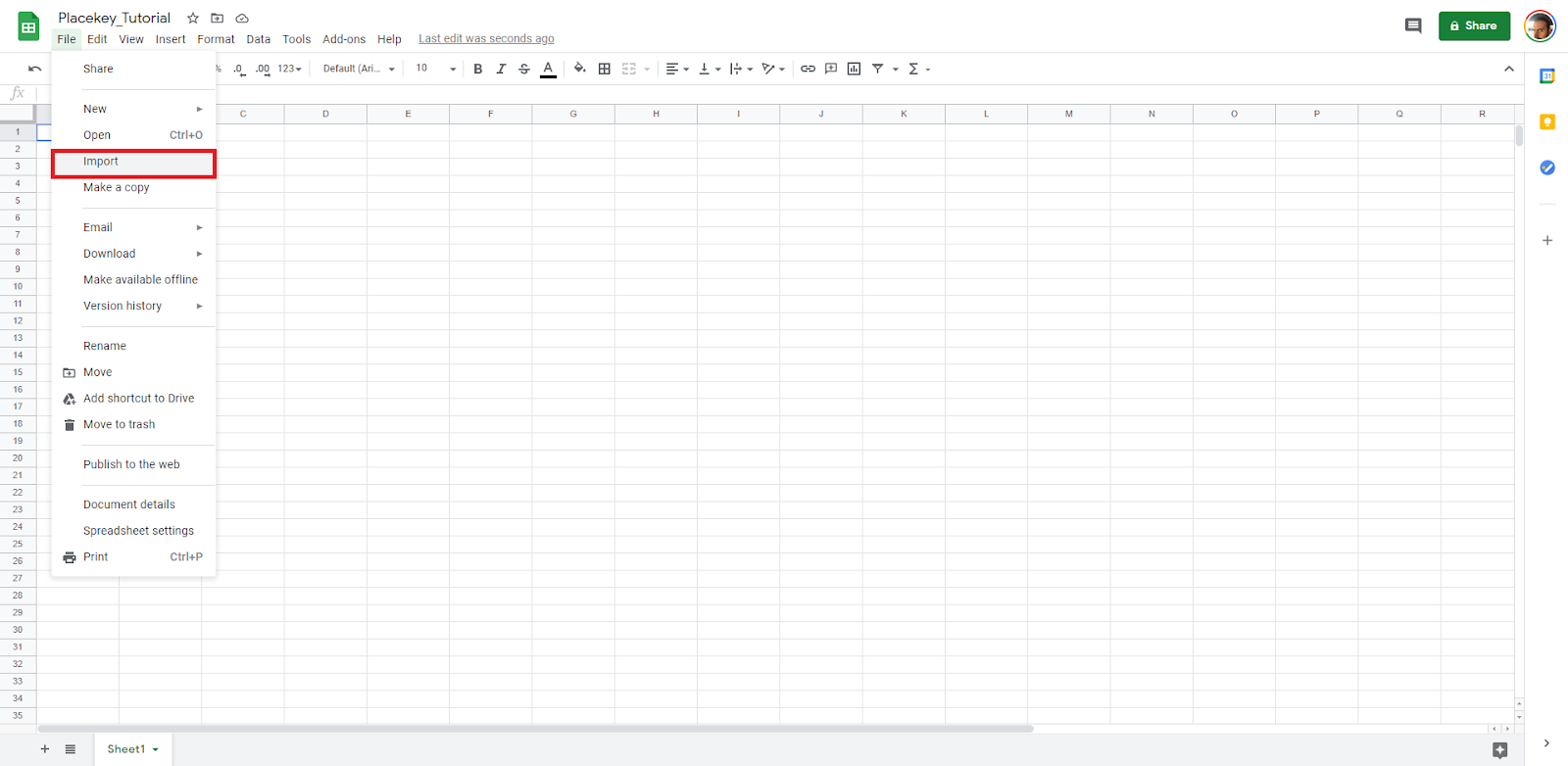
2. Once in Google Sheets, go to File>Import>Your_File_Path
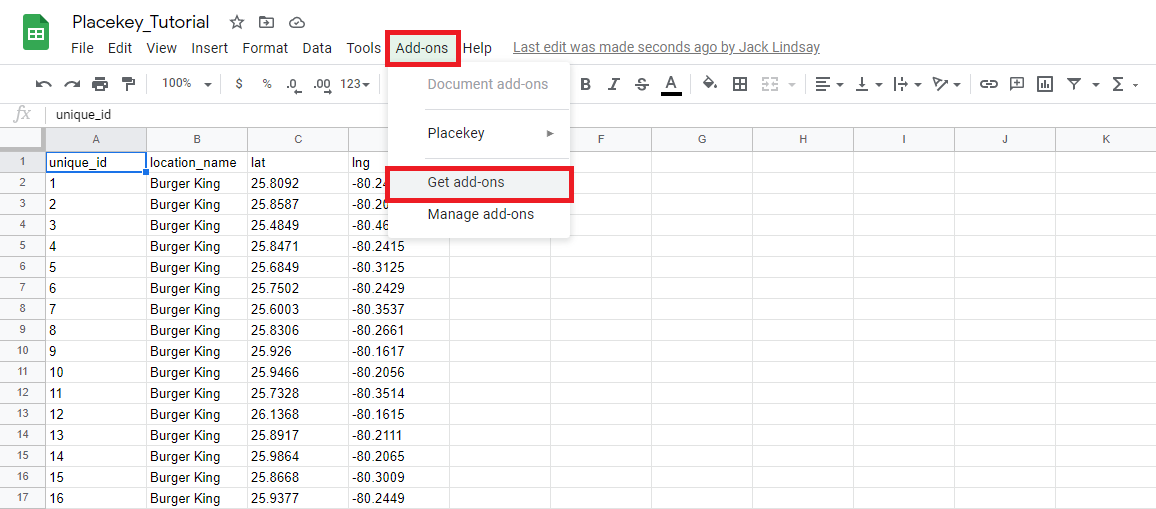
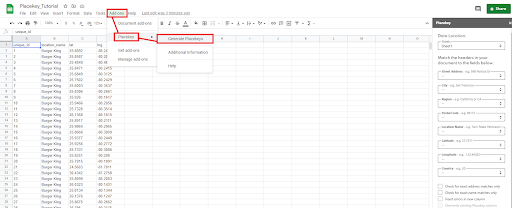
3. Once your data has been imported, go to Add-ons>get Add-ons and download Placekey
4. After you have installed Placekey, the first time you use it, you will need to add your API key that you got from the Getting Started section
5. Once Placekey has been installed, click on the Add-ons tab again and this time you should see Placekey listed below. Click Add-ons>Placekey>Generate Placekeys
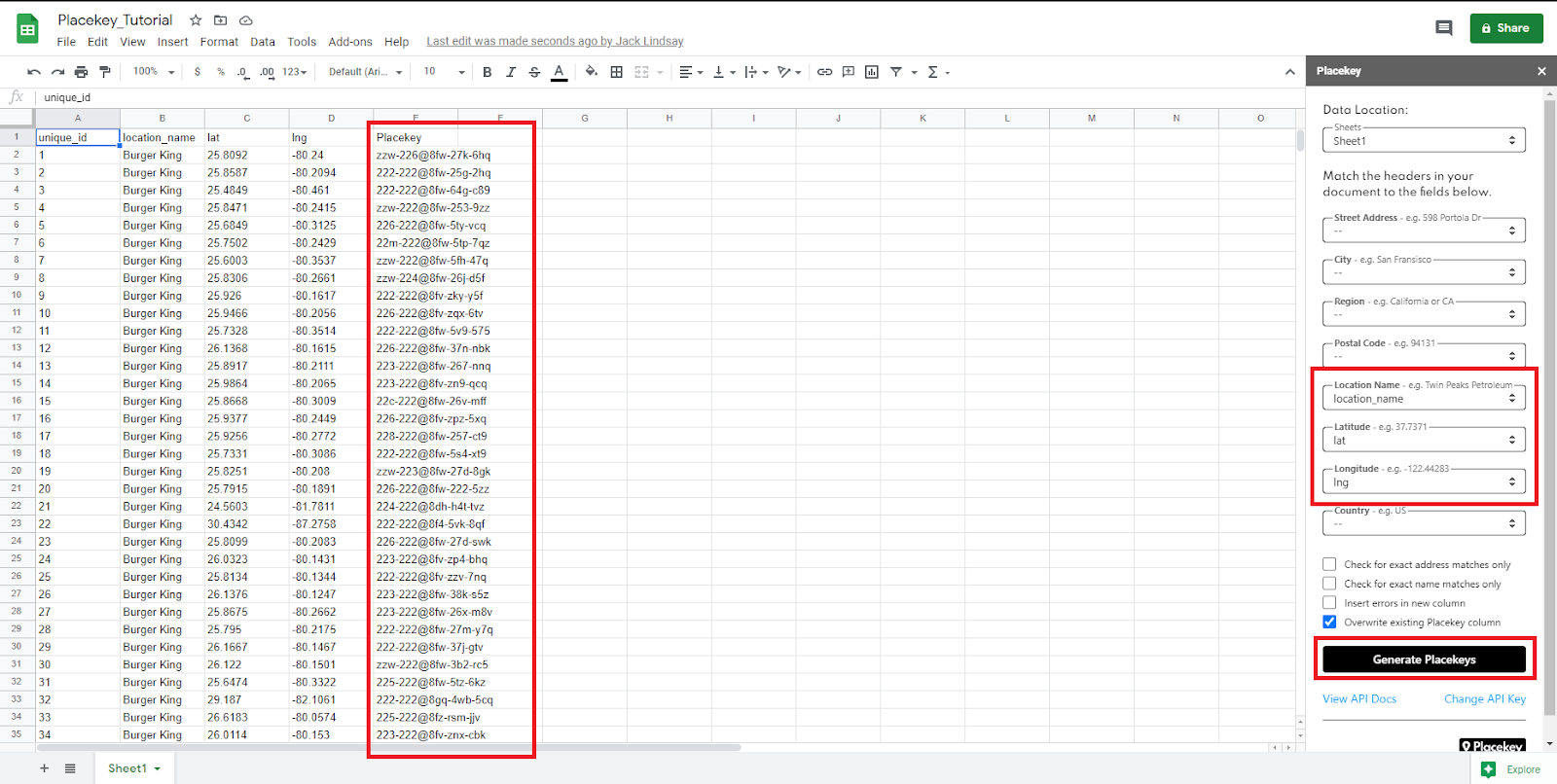
6. Now, it is as simple as selecting the correct fields and clicking ‘Generate Placekeys’
Congratulations! You now have Placekeys on your data
Option 2: Python
As aforementioned, the Code access to Placekey API is a bit more intense, but is better for large batches. If you would prefer to work with the code directly, see the Colab Notebook here.
1. To start, pip install the necessary Python libraries and import them into the python file (Placekey install instructions HERE)
import pandas as pd
import numpy as np
import json
from placekey.api import PlacekeyAPI
2. Next, set your API key by either hard coding it in or linking it to a saved csv elsewhere on your PC; and then set your file path
placekey_api_key = "Your API key here"
pk_api = PlacekeyAPI(placekey_api_key)
### add your FP below
data_path = r"C:\Users\jack\Desktop\placekey_proj\fastfood_lat_lng_only.csv"
3. Set your Data Typesto string so no leading zeros are dropped
4. (optional) - If your file does not have a unique ID to rejoin your future merge on, you can enumerate the index to create one
li = []
for x in range(orig_df.shape[0]):
li.append(f"{x}")
orig_df['id_num'] = li
5. Set your column map (AKA tell Placekey which column contains what) and add in a country_code column to help narrow Placekey’s search
query_id_col = "unique_id" # this column in your data should be unique for every row
column_map = {query_id_col: "query_id",
"location_name" : "location_name",
"lat": "latitude",
"lng": "longitude"
}
df_for_api = orig_df.rename(columns=column_map)
cols = list(column_map.values())
df_for_api = df_for_api[cols]
# add missing hard-coded columns
df_for_api['iso_country_code'] = 'US'
df_for_api.head()
6. Clean the data and see if there are any Null/NaN/etc values
df_clean = df_for_api.copy()
possible_bad_values = ["", " ", "null", "Null", "None", "nan", "Nan"] # Any other dirty data you need to clean up?
for bad_value in possible_bad_values:
df_clean = df_clean.replace(to_replace=bad_value, value=np.nan)
print("FYI data missing from at least 1 column in the following number of rows:")
print(df_clean.shape[0] - df_clean.dropna().shape[0])
print("Some examples of rows with missing data")
df_clean[df_clean.isnull().any(axis=1)].head()
data_jsoned = json.loads(df_clean.to_json(orient="records"))
print("number of records: ", len(data_jsoned))
print("example record:")
print(data_jsoned[0])
7. Check a single response to make sure everything is working before you do a full API batch request
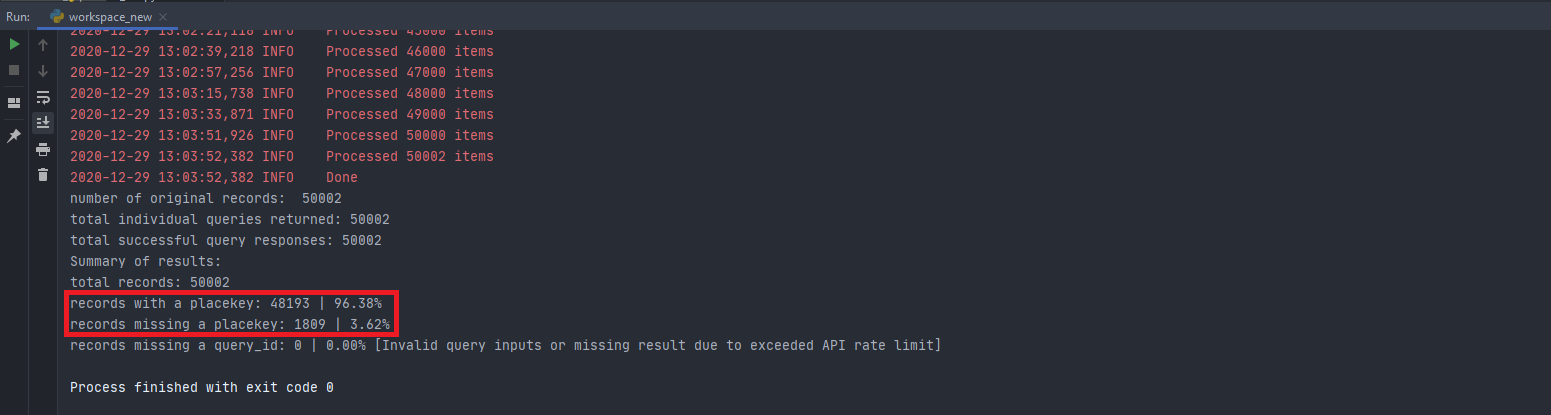
10. Get a final print out of how successful the query was (match/loss ratio)
print("Summary of results:")
total_recs = df_join_placekey.shape[0]
print("total records:", total_recs)
print("records with a placekey: {0} | {1:.2f}%".format(df_join_placekey[~df_join_placekey.placekey.isnull()].shape[0], df_join_placekey[~df_join_placekey.placekey.isnull()].shape[0]*100/total_recs))
print("records missing a placekey: {0} | {1:.2f}% ".format(df_join_placekey[df_join_placekey.placekey.isnull()].shape[0], df_join_placekey[df_join_placekey.placekey.isnull()].shape[0]*100/total_recs))
print("records missing a query_id: {0} | {1:.2f}% [Invalid query inputs or missing result due to exceeded API rate limit]".format(df_join_placekey[df_join_placekey.query_id.isnull()].shape[0], df_join_placekey[df_join_placekey.query_id.isnull()].shape[0]*100/total_recs))
11. Prepare for export, then export final DataFrame to CSV for analysis or future merges on Placekey
Your Python output should look like the following - with a 96.38% match rate:
Note: Some addresses may be closed or the data may be messy, but in general you can expect high match rates like we see in this tutorial
Optional: Merge with SafeGraph
There are many things you can do with your new Placekeys. The most common of which is to use your Placekeys to merge your POI dataset with another POI dataset with ease.For example, try merging this dataset with SafeGraph on Placekey in order to generate amazing foot traffic data! (find link to Demo SafeGraph data HERE)And that's it! You now have location data with your restaurant data that will allow you to check visits to each location and more!