Product updates, industry-leading insights, and more
Using Python for Address Matching: How To + the 6 Best Methods
by Placekey
Address matching can be a long, tedious, challenging process that doesn’t always yield great results. It’s also restricted by very specific formatting conventions and yet inputs are often open for the user, resulting in a variety of different formats and spellings of the same address.
Manual address matching and legacy software are extremely time-consuming and difficult to match addresses with any degree of flexibility. With programming languages, you can run scripts that will automatically execute tasks, saving you time and increasing accuracy. One of the most popular methods of scripting is Python, which can be leveraged to perform better address matching.
What is Python address matching?
Address matching problems Python solves
Why you should use Python for address matching
Downsides of using Python for address matching
Top 6 methods & tools for Python address matching
By the end of this article, you’ll know what address matching is and the best methods to use Python to match addresses.
What is Python address matching?
Python address matching is simply address matching using the Python programming language. As a high-level and general-purpose programming language, Python is widely used because of its code readability. Using Python for address matching automates much of the process, increasing your ability to accurately match addresses.
With Python, you can compare multiple records, automating their processing and greatly increasing the speed at which you can do this. As you can imagine, manually matching records takes significant time. With Python, you can set up your data sets, establish rules for comparison, and then compare the data sets to match addresses.
Address matching is actually the process of matching an address in a database to an actual location on a map, sometimes known as geocoding. In many cases, address matching using Python is actually address validation and address standardization, where you compare addresses to ensure they are accurate, and to match addresses for deduplication. To better understand this, we explain why address validation isn’t a substitution for address matching.
Address matching problems Python solves
Address matching can be a tedious, time-consuming process. In some cases, it’s barely possible to do manually. Fortunately, scripting languages like Python solve a number of the shortcomings of direct address matching.
Automating manual processes - Rather than requiring manual comparisons, you can use Python to run comparisons that determine whether addresses are a true match or not, or give you partial truth scores.
Manual processing cannot be batched - Software packages are great at doing one address match at a time, but when you need to batch process, it can take a long time.
Providing a match likeliness ratio - By comparing two addresses, you can determine the ratio of an exact match, allowing you to make judgement calls (or automate these judgement calls for you).
Assess a match regardless of formatting - Implement a likeness ratio that determines how closely addresses match, without accounting for the order of the components. In this case, multiple address formats can be assessed. (i.e. 123 Main Street, Unit 4 versus 123 Unit 4, Main Street).
Why you should use Python for address matching
There is no particular reason to use Python specifically for address matching, as there are alternative methods. Mainly, Python would be your go-to if you like to use Python or if your project requires it because of the other programs you use or the SDK you currently use.
I know and prefer Python: You already use or are familiar with Python, and prefer it to alternative programming languages available.
It is the only SDK available to me: Whether it’s because of the other solutions you already use, or because of the functionality you want, Python may be the only SDK available to you.
My company or project demands it: If your company uses Python across the board, or you need to use it on a specific project, you may be restricted to Python for address matching.
A lot of this decision comes down to whether you are using an SDK, and need to either use a language that already works with the set of tools you currently use, or if you are using a direct API.
An SDK may require Python, or it may be the easiest language to use, as all tools will communicate more effectively.
Downsides of using Python for address matching
Despite Python being a viable solution for many of the common address matching problems you’d run into, there are still shortcomings. We cover the main problems with using Python for address matching, and we’ll also discuss why Placekey’s tool offers a superior solution without any of the downsides of Python address matching.
Requires significant processing: Processing this level of information takes a lot of time, regardless of the fact that Python automates it. With Placekey’s universal identification system, you don’t require any processing for address matching to occur.
Data has to be processed properly for good results: To get accurate results you can be confident in, you need to preprocess your data properly. This means cleaning and standardizing formats, segmenting data, and more, which takes significant time (and doesn’t always end in a positive result).
Challenging to account for phonetic differences: Many people input addresses based on how they sound, which can lead to input errors. While Python can account for this using the Levenshtein distance, there is still room for error. Placekey’s universal identifier eliminates the need for this, as you use an alphanumeric code.
Requires experience with Python: To effectively match addresses using Python, you’ll need to be familiar with Python. If someone on your team is not already trained to use Python, it will be a steep learning curve to adopt Python and then learn how to use it effectively for address matching.
Top 6 methods & tools for Python address matching
There are a number of ways to use Python for address matching that allow you to find exact and partial matches. As Python is a rather general coding language that has many applications, you can use it in a variety of ways depending on the output you are looking for.
We will start with some of the more basic methods, and work our up to more complex ways of address matching.
Method 1: Using deterministic address matching
One of the most basic ways to match addresses using Python is by comparing two strings for an exact match. It’s important to note that this won’t account for spelling mistakes, missing words, and when parts of the address are entered in different orders. To determine whether something is absolutely true or false.
Method 2: Using data preprocessing for a better match
Comparing for an exact match is very limiting, as all characters must match exactly, including their case. To increase your chances of a match, you should first convert your addresses to lower case. Oftentimes, users forget to input characters in the correct case, especially in the case of street names like ‘McCormick’, where users fail to input the middle C in upper case.
Without converting to lowercase, we get false result:
By first converting both of the strings you are comparing to lower case, a complete match can be made without the character case affecting it. With how often errors are made inputting addresses, this can be extremely useful and save manual review.
Method 3: Using fuzzy logic for partial truths
The next method to use is the Levenshtein distance, which will allow you to account for partial matches, rather than only exact matches. This is made possible using fuzzy logic, which can account for partial truth. This allows you to determine the likelihood of a match between 1 (exact match) and 0 (not an exact match). The Levenshtein distance of two strings (a and b; of length |a| and |b| respectively), can be calculated using the following formula:
You can use the Levenshtein distance to assess addresses for a true match, instead determining how likely they are to be a match. This will allow you to better assess addresses, while accounting for input errors, misspellings, word order, and more.
You can input your strings for comparison, using the Levenshtein distance to get a partial match score.
This gives a very high likelihood of a match. However, there are ways we can increase our chances of determining a true match. If we combine this with method 2, and first convert our address to lowercase, it increases the likelihood of a match.
You can also first convert both addresses to lower case during this check
As you can see, the Levenshtein distance used with strings in lowercase gives us a higher rating, and a better indication of a match.
You can also perform the above using the Levenshtein package within Python:
import Levenshtein as lev
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = lev.distance(Str1.lower(),Str2.lower()),
print(Distance)
Ratio = lev.ratio(Str1.lower(), Str2.lower())
print(Ratio)
Expected output:
(1,)
0.9473684210526315
It is essential to preprocess your data prior to analyzing, as it can have a significant impact on your results, improving accuracy. Over time, you can get better at it, determining this difference with greater accuracy, efficiency, and automation.
This Python package enables fuzzy matching between two panda dataframes using sqlite3’s Full Text Search. Once matches have been detected, it determines their match score using probabilistic record linkage. You can use the match quality scores to determine the likelihood of a true match.
First, you need to install fuzzymatcher. To do this, you will need a build of sqlite that includes FTS4.
To install fuzzymatcher, enter the following:
pip install fuzzymatcher
Once installed, you can pair two address tables to find a match score rating.
This will return a report of the fuzzy match rating. You can then determine if these are true matches or not, and further investigate only relevant results.
You can then automatically identify addresses by setting a threshold that uses the partial match to determine if an address matches. For example, you can set a threshold of 0.8, and any address with a score higher than this will be determined a match.
You can easily link records easily using Python Record Linkage Toolkit, helping you deduplicate records and manage your data effectively. It uses Python’s pandas, which is a flexible data analysis and manipulation library built specifically for Python and can be used to match addresses bad on parameters. You receive a match score, that helps you determine the likelihood of a true match between strings.
First, install the library using pip, and then set up an explicit index column to read the data:
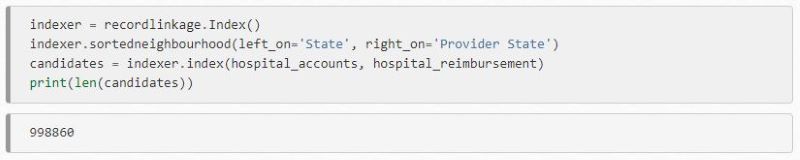
You can then define linkage rules, allowing you to leverage Record Linkage Toolkit’s complex configuration capabilities. Create an indexer object by doing the following:
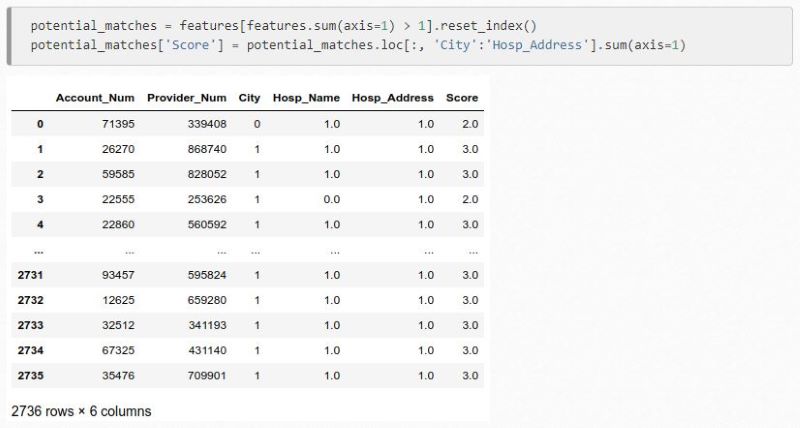
This can then be used to evaluate the potential matches. The most likely problem is that there can be a high number of paired records, some of which will be incorrect. This also results in too much unrelated information being captured. Instead, determine how many comparisons will be run, so you can potentially restrict your comparison and save processing time.
There are a number of ways to refine your comparison and speed up the processing, saving you time. Specify your search for the information you need most, and set up thresholds to automate address matching.
Use blockers to eliminate certain elements from the search, so that you can refine your search a lot. For example, you can set up a blocker on the city to ensure you are only matching addresses within a specific municipality.
With your search refined to the relevant data sets, you will be compute this much faster. You can address matches quickly and efficiently, without matching addresses you don’t need. Next, you need to ensure that you account for spelling mistakes, allowing for flexibility in user input. To do this, set up a SortedNeighborhood algorithm to check misspellings (i.e. “Tenessee” vs “Tennessee”).
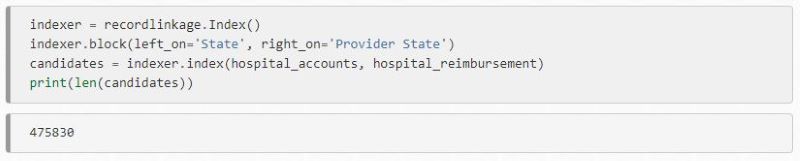
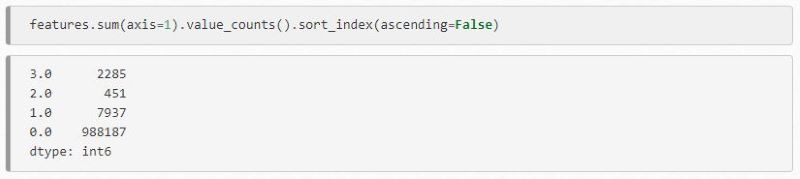
Once done all this, you will end up with a features DataFrame. Column labels are based on the elements you set up for comparison, so that you can easily see them displayed in the table. A 1 notes a full match; a 0 notes a full negative.
We now know exactly how many matches there are, and how many of the sets didn’t match. The rows with the most matches are likely to be full matches, so you can work your way down, ignoring ones without any matches at all. You can compare data sets and then add quality scores to determine the likelihood of a match.
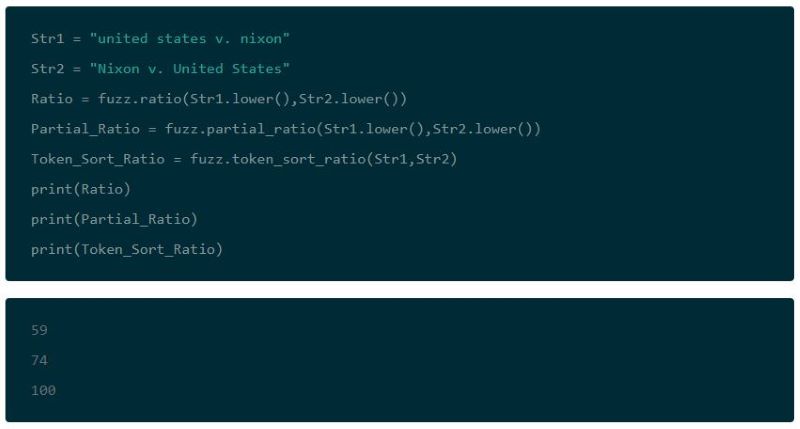
While the Levenshtein and Damerau-Levenshtein distances are extremely useful, they struggle to match address information that is input out of order. While there is standardized formatting for input, some people still make errors and different systems format information differently. For instance, users can input the same address in the two ways below:
123 Main Street, Unit 4
123 Unit 4, Main Street
In the case above, the Levenshtein and Damerau-Levenshtein distances would need to have very low thresholds for addresses to be matched, as many characters would need to be transposed. That would result in many false positives, and ultimately result in poor results.
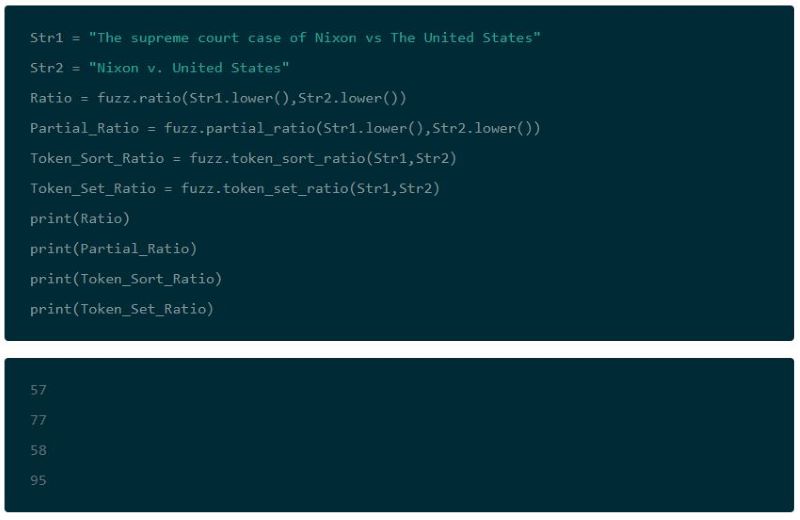
FuzzyWuzzy solves this problem by first tokenizing strings and preprocessing them (by removing punctuation and converting them to lowercase). This makes it possible to compare addresses that aren’t ordered the same.
This also lets you pair data that was input in entirely different formats. From formatted fields to a sentence, you can extract the meaningful portions of data, and then easily compare the elements separately.
Being able to match addresses that are out of order will help you match addresses with greater accuracy. You can then deduplicate your data more effectively, combining records.
Now you know how to use deterministic data matching (where you get a yes or no match) and probabilistic data matching (where you get a partial match score, indicating the likelihood of a full match) for address matching in Python. Use one or any combination of the methods above, dependent on how flexible your address matching needs to be.