Given a POI dataset without location names, we can use Placekey to identify specific POIs. To do this, we set the location_name parameter equal to 'Starbucks'. Not every location is a Starbucks. In fact, most aren't. By setting location_name to 'Starbucks', we tell the Placekey API to only return Placekeys for Starbucks locations. In this way, we are able to identify Starbucks locations from name-less permit data.
Take a look at our Google Colab notebook for this tutorial to access the code and run it yourself!
Getting Started
Before moving forward, it might be a good idea to get more familiar with Placekey. There are a growing number of resources available:
In the first code block, we install the placekey package in our Google Colab environment and import the necessary packages.
!pip install placekey
from placekey.api import PlacekeyAPI
import pandas as pd
import numpy as np
from ast import literal_eval
import json
from google.colab import drive as mountGoogleDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
Authentication
Run this code block to authenticate yourself with Google, giving you access to the datasets.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
print("You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!")
Set API key
Replace the asterisks below with your Placekey API key. If you don’t have one yet, it’s completely free.
placekey_api_key = "***************" # fill this in with your personal API key (do not share publicly)
pk_api = PlacekeyAPI(placekey_api_key)
First, define a couple functions to make it easier to read in the dataset. These functions will read a tutorial CSV from Google Drive without you having to upload your own data.
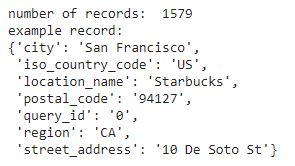
In this step, we create a new dataframe with just the address columns from the permits dataset. The columns are renamed and reformatted to conform to the Placekey API. Additionally, we add a location_name column to 'Starbucks' for every row, along with city = 'San Francisco' and region = 'CA'.
The full Placekeys correspond to the Starbucks locations. A Placekey is "full" if it has the POI and address components, for a total of 15 characters (not counting hyphens and "@"). We filter the dataframe below to rows with full Placekeys, finding 232 permits for Starbucks, with 49 unique locations.
In this tutorial, we learned how to find specific locations in name-less POI data using the Placekey API. Specifically, given a dataset of San Francisco permits, we identified which permits corresponded to Starbucks locations. By making each request with location_name = 'Starbucks', we forced the Placekey API to only return full Placekeys for addresses corresponding to Starbucks locations.
Join the SafeGraph Community, a free Slack community for geospatial data enthusiasts. Receive support, share your work, or connect with others in the GIS community.