This tutorial will teach you how to join POI and non-POI datasets with Placekey using Python in a Google Colab environment.
Our POI dataset is a subset of SafeGraph Places, which contains info on all POIs in San Francisco. Our non-POI dataset contains the latitude/longitude coordinates for all parking meters in San Francisco.
The goal of this tutorial is to get you familiar with the process of joining POI data with non-POI data on Placekey, including the limitations and considerations to be aware of.
In the first code block, we install the Python Placekey package in our Google Colab environment and import the necessary packages.
!pip install placekey
from placekey.api import PlacekeyAPI
import placekey as pk
import pandas as pd
from ast import literal_eval
import json
from google.colab import drive as mountGoogleDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
Expected output:
Authentication
Run this code block to authenticate yourself with Google, giving you access to the datasets.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
print("You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!")
Expected output:
Set API key
Replace the asterisks below with your Placekey API key. If you don’t have one yet, it’s completely free.
# placekey_api_key = "*****************" # fill this in with your personal API key (do not share publicly)
pk_api = PlacekeyAPI(placekey_api_key)
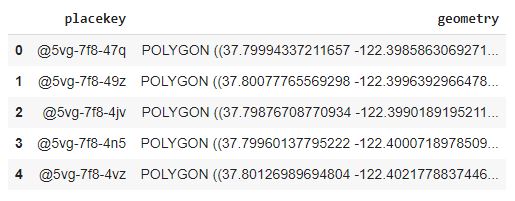
The Places dataset contains info about all POIs in San Francisco. This particular version of Places is from the October 2020 release. Column descriptions and more information can be found in the docs.
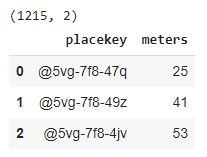
The San Francisco Parking Meters dataset comes from DataSF. It was pulled on January 10, 2021. When we read the data in, we're filtering to just a few columns.
As can be seen above, SafeGraph Places comes with a Placekey column built-in. The Parking Meters dataset, on the other hand, does not have a Placekey column, so we need to add Placekeys to that dataset. There are several ways to add Placekeys to a dataset (including some no-code integrations!), which you can find on the Placekey website. In this example, we will use Python’s Placekey package.
Map columns to appropriate fields
In this step, the columns are renamed to conform to the Placekey API. More specifically, OBJECTID is mapped to query_id, LATITUDE is mapped to latitude, LONGITUDE is mapped to longitude.
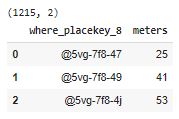
You'll notice the Parking Meter Placekeys only have a WHERE component (9 characters when excluding '-' and '@'), while the Places Placekeys have WHERE and WHAT (15 characters when excluding '-' and '@'). The parking meters only have latitude/longitude coordinates to identify their locYou'll notice the Parking Meter Placekeys only have a WHERE component (9 characters when excluding '-' and '@'), while the Places Placekeys have WHERE and WHAT (15 characters when excluding '-' and '@'). The parking meters only have latitude/longitude coordinates to identify their locations. This means the parking meters are only associated with an area (represented by an H3 hexagon) instead of an address/POI.
To match these non-POI parking meters with our POIs, we must reduce the POI Placekeys to just the WHERE component. Then our merge will be apples-to-apples.
Joining on Placekey: Counting Nearby Parking Meters
Now, we are ready to join the datasets on Placekey. For simplicity, our use case will be to count nearby parking meters for each POI.
How would we solve without Placekey?
Without Placekey, we would need to calculate the distance between each parking meter and POI to determine whether or not we consider it "nearby." With over 33,000 parking meters and 23,000 POIs, we would need to compute over 759 million distances.
Method #1: Only Same Hex
First, we will count parking meters in the same hex as each POI. There are several shortcomings to this approach, which we will address momentarily. We group the meters by Placekey, counting the number of parking meters that reside in each hex.
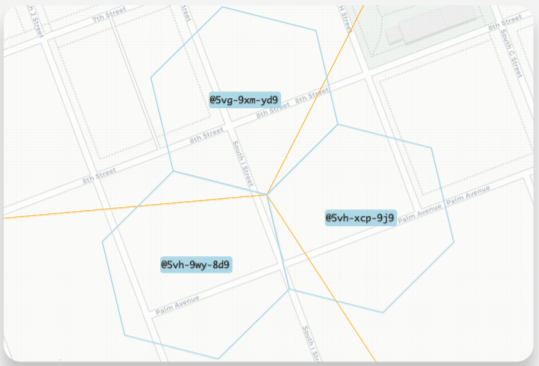
This approach is simple, but it has a problem. What if a POI is located near the edge of its hexagon? This approach might not count parking meters that could be right next to the POI if they happen to be in different hexagons. For example, the orange dot below shares a hexagon with the black dot, but it is clearly much closer to the blue dot.
Method #2: Neighboring hexes by prefix
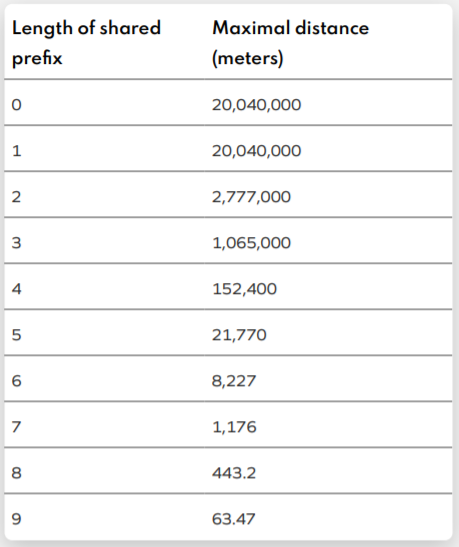
We can eliminate some of the problems with our previous approach by looking at the length of the shared prefix of the WHERE Placekeys. See the chart below from the Placekey whitepaper. Suppose we are interested in counting the parking meters within 443.2 meters of each POI in San Francisco. We can use the WHERE portion of Plackey to estimate these counts.
In the last section we merged on the entire 9 characters of the WHERE part of each Placekey. In this section, we match on the first 8 characters to include some of the adjacent hexes.
Although this approach is better than the "Only Same-Hex" approach, we still run the risk of missing nearby parking meters that happen to have different parent hexes. The image below shows an example of this. We can do better still.
Method #3: All neighboring hexes
A more thorough solution to estimate the number of nearby parking meters is to include the counts for all adjacent hexes. Python's placekey package has some useful functions to make this easier.
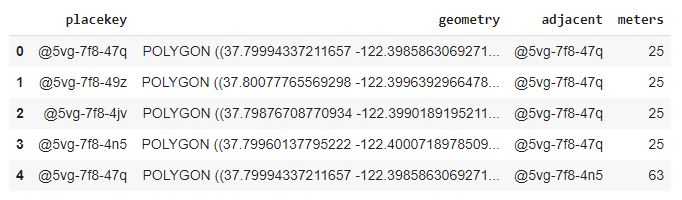
First, we add a column called geometry for the shape of each Placekey hexagon.
Fourth, we group by the original Placekey, taking the sum of parking meter counts for all adjacent Placekey hexagons. This includes the count of parking meters in the original Placekey hexagon.
The WHERE Placekeys represent hexagonal spaces (not perfect circles), so these counts are just estimates.
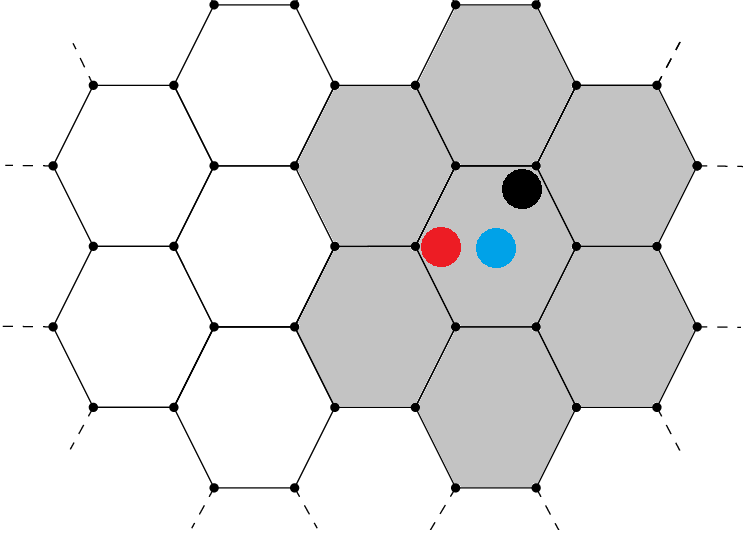
All POIs in the same hexagon are given the same estimates, even if they are on opposite sides of the hexagon. See the image below. If POIs are at the black, red, and blue dots, their parking meter counts include the counts of parking meters in each of the hexagons that are shaded gray.
Keep in mind, each hexagon has a diameter of about 132 meters, which means we can join non-POI data to POI data at high resolution.
Conclusion
In this tutorial, we demonstrated how to join POI and non-POI datasets with Placekey. This is made easy with the WHERE portion of Placekey, which corresponds to a unique H3 hexagon on Earth's surface, with a diameter of about 132 meters.
Along with joining the datasets, we also covered some considerations to keep in mind. For our use case of estimating the number of nearby parking meters in San Francisco, we sacrificed some accuracy to avoid computing 759 million distances for the 23,000+ POIs and 33,000+ parking meters in the city.
When joining POI and non-POI datasets, the exact process may vary to fit your needs and assumptions. This tutorial gives you the background needed to simplify that process with Placekey.
Join the SafeGraph Community, a free Slack community for geospatial data enthusiasts. Receive support, share your work, or connect with others in the GIS community.